
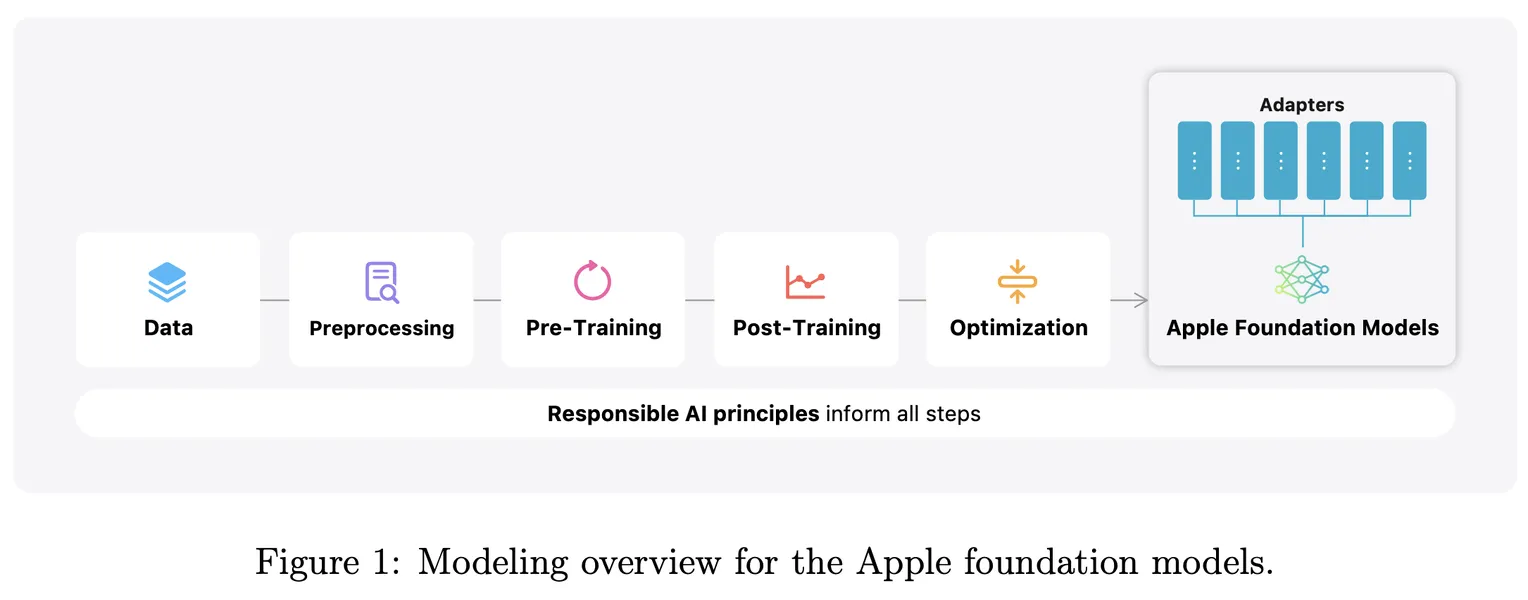
Modelele de Limbaj Fundamentale Apple Intelligence

Acest document conturează modelele de limbaj fundamentale ale Apple, create cu meticulozitate pentru a îmbunătăți caracteristicile Apple Intelligence pe platformele iOS, iPadOS și macOS. Este vorba despre două modele principale: modelul on-device cu 3 miliarde de parametri, denumit AFM-on-device, și modelul mai extins, bazat pe server, cunoscut sub numele de AFM-server. Ambele modele sunt construite ca arhitecturi Transformer dense, doar decodere, optimizate pentru eficiență, fiind adaptate pentru a executa o gamă largă de sarcini cu o mare precizie și responsabilitate.
Regimul de antrenament pentru aceste modele este extins și multifacetic. Acesta începe cu un pre-antrenament de bază pe un set de date bogat și divers, care cuprinde 6.3 trilioane de token-uri, care oferă o fundație robustă pentru înțelegerea limbajului. După aceasta, modelele trec printr-un pre-antrenament continuu, în care procesează încă 1 trilion de token-uri la lungimi de secvență mai mari. Această etapă este completată de extinderea contextului, care încorporează 100 de miliarde de token-uri la o lungime a secvenței de 32k, sporind și mai mult capacitatea lor de a gestiona input-uri complexe.
Odată ce etapele inițiale de antrenament sunt complete, se aplică o serie de tehnici de post-antrenament. Acest lucru include fine-tuning supervizat și învățare prin întărire din feedback-ul uman (RLHF), utilizând metodologii inovatoare, cum ar fi comitetul de predare iterativ (iTeC) și descendența prin oglindire cu estimarea leave-one-out (MDLOO). Aceste tehnici asigură că modelele nu doar că învață din cantități vaste de date, ci și că își rafinează răspunsurile pe baza interacțiunilor umane din lumea reală.
Pentru a spori adaptabilitatea și eficiența modelelor, acestea sunt specializate suplimentar folosind adaptoare LoRA (Low-Rank Adaptation). În plus, se utilizează strategii de optimizare, cum ar fi cuantizarea și reducerea, pentru a asigura funcționarea eficientă a acestor modele pe dispozitive, făcându-le potrivite pentru medii mobile și edge.
Rezultatele benchmark-ului relevă faptul că modelul AFM-on-device depășește semnificativ alternativele open-source mai mari, cum ar fi Mistral-7B, în special în sarcini de urmare a instrucțiunilor și în sarcini matematice. Între timp, modelul AFM-server demonstrează capabilități competitive față de GPT-3.5, evidențiind puterea sa în sarcini de uz general. Notabil, ambele modele excelează în evaluările de siguranță, reflectând angajamentul neclintit al Apple față de desfășurarea responsabilă a tehnologiilor de inteligență artificială.
Acest document subliniază metodologiile sofisticate și optimizările implicate în dezvoltarea acestor modele AI de înaltă performanță, eficiente și responsabile, poziționând Apple în fruntea inovației în domeniul AI.
Introducere
Într-o eră în care inteligența artificială evoluează rapid, Apple se află în fruntea inovației prin introducerea modelelor sale fundamentale de limbaj, concepute pentru a susține noua generație de Apple Intelligence pe iOS, iPadOS și macOS. Aceste modele—AFM-on-device, un model compact cu 3 miliarde de parametri, și AFM-server, un omolog mai puternic bazat pe server—încarnă angajamentul Apple de a crea soluții AI eficiente, responsabile și axate pe confidențialitate.
Acest document analizează metodologiile sofisticate din spatele acestor modele, care au fost create cu meticulozitate pentru a oferi performanțe excepționale într-o gamă largă de sarcini. Cu un cadru robust de antrenament care încorporează peste 6,3 trilioane de token-uri, capabilități extinse de context și tehnici avansate de post-antrenament, modelele de limbaj ale Apple nu sunt doar construite pentru acuratețe, ci și proiectate cu considerații de siguranță și etică în centrul lor. Pe măsură ce explorăm procesele complexe de antrenament, strategiile de optimizare și benchmark-urile de performanță, devine clar că aceste modele reprezintă un salt semnificativ înainte în tehnologia AI, fiind pregătite să îmbunătățească experiențele utilizatorilor, păstrând în același timp valorile Apple legate de confidențialitate și responsabilitate.
Apple a introdus modelele sale fundamentale de limbaj care susțin caracteristicile Apple Intelligence pe iOS, iPadOS și macOS. Aceste modele includ un model on-device cu 3 miliarde de parametri și un model mai mare bazat pe server. Concepute pentru a efectua o gamă largă de sarcini eficient, precis și responsabil, aceste modele demonstrează angajamentul Apple față de AI avansată, asigurând în același timp confidențialitatea utilizatorilor și eficiența dispozitivului.
Prezentare Generală a Metodei
Modele: AFM-on-device și AFM-server
Modelele fundamentale ale Apple constau din două tipuri principale:
- AFM-on-device: Un model de aproximativ 3 miliarde de parametri optimizat pentru performanța pe dispozitive.
- AFM-server: Un model mai mare și mai puternic, conceput pentru sarcini bazate pe server.
Ambele modele sunt modele Transformer dense, doar cu decodoare, având mai multe optimizări arhitecturale pentru o eficiență îmbunătățită.
Procesul de Antrenament
Procesul de antrenament pentru aceste modele implică trei etape principale:
-
Pretrain de bază:
- Dataset: Un set de date diversificat și de înaltă calitate, care cuprinde 6,3 trilioane de token-uri din pagini web, seturi de date licențiate, cod, conținut matematic și seturi de date publice. Aceste date sunt filtrate și procesate cu meticulozitate.
- Obiectiv: Dezvoltarea unei înțelegeri fundamentale solide.
-
Pretrain continuu:
- Durata: 1 trilion de token-uri la lungimi de secvență mai mari.
- Amestec de date: Ajustat pentru a îmbunătăți capabilitățile modelului pe contexte extinse.
-
Extinderea Contextului:
- Domeniu: 100 de miliarde de token-uri la o lungime de secvență de 32k.
- Scop: Îmbunătățirea capacității modelului de a gestiona eficient sarcinile cu contexte lungi.
Îmbunătățiri Post-Antrenament
Pentru post-antrenament, Apple folosește tehnici avansate:
- Fine-tuning Supervizat: Ajustează modelul pentru a se alinia cu sarcini specifice.
- Învățare prin Reinforțare din Feedback-ul Umann (RLHF): Încorporează feedback-ul uman pentru a rafina ieșirile modelului.
Tehnici Noi
- Comitetul de Învățare Iterativă (iTeC): O tehnică de îmbunătățire iterativă a capabilităților modelului prin revizuiri de către un comitet de experți.
- Descentrarea Oglindită cu Estimarea „Lasă-Unul-De-O-Side” (MDLOO): O tehnică avansată de optimizare pentru ajustarea eficientă a parametrilor modelului.
Specializare și Optimizare
Modelele sunt specializate suplimentar pentru sarcini specifice folosind adaptoare LoRA (Low-Rank Adaptation), care pot fi încărcate dinamic. Pentru a asigura eficiența, în special pentru modelele pe dispozitive, se aplică optimizări extinse, cum ar fi cuantizarea și tăierea.
5 Puterea Funcțiilor Apple Intelligence
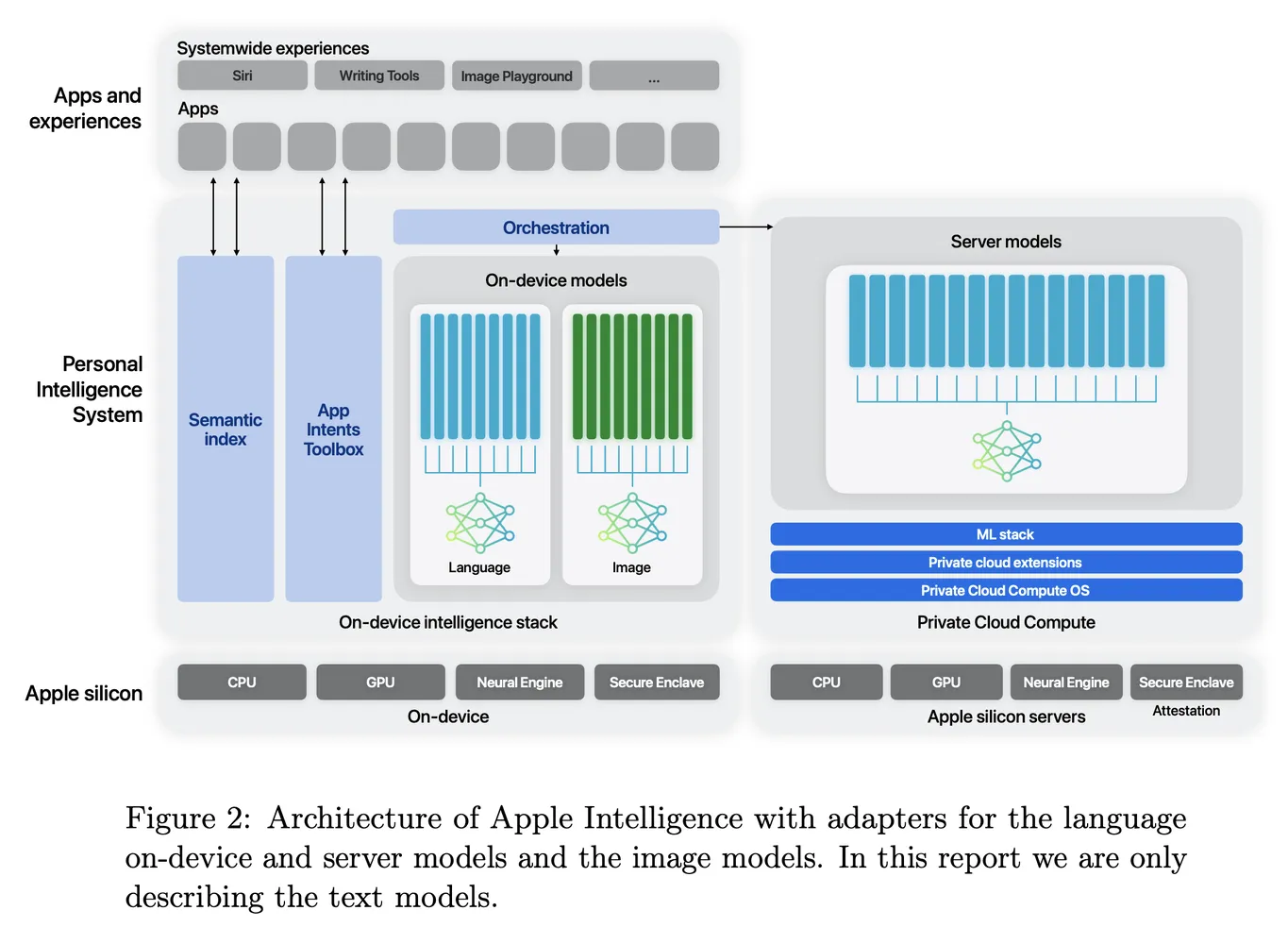
Modelele fundamentale dezvoltate pentru Apple Intelligence sunt meticulos concepute pentru a îmbunătăți experiența utilizatorului pe iPhone, iPad și Mac. Apple Intelligence servește ca un sistem de inteligență personală care folosește modele de limbaj avansate pentru a oferi funcționalități inteligente și conștiente de context. Central în acest sistem este înțelegerea că performanța acestor modele nu este doar o chestiune de capabilități generale, ci depinde de eficiența lor în realizarea sarcinilor specifice relevante pentru utilizatori.
Pentru a atinge o performanță excepțională a sarcinilor, Apple a implementat o arhitectură versatilă care utilizează adaptoare swapabile la runtime. Această arhitectură permite unui singur model fundamental să se specializeze dinamic pentru o gamă diversificată de sarcini, transformându-și eficient funcționalitatea în timp real. Această capacitate permite chiar și modele mai mici să atingă niveluri de performanță de vârf prin fine-tuning țintit.
5.1 Arhitectura Adaptorului
Arhitectura Apple Intelligence este condusă de utilizarea adaptoarelor LoRA (Low-Rank Adaptation)—module de rețea neurală mici integrate în diverse straturi ale modelului de bază. Acest design permite fine-tuning-ul specific pentru sarcini fără a altera parametrii originali ai modelului pre-antrenat. Concentrându-se pe matricile de proiecție liniară din straturile de auto-attention și cele complet conectate, Apple menține cunoștințele fundamentale ale modelului în timp ce îl personalizează pentru a îmbunătăți performanța în aplicații specifice.
De exemplu, parametrii adaptorului sunt reprezentați folosind 16 biți, iar pentru modelul de ~3 miliarde de parametri, acești parametri ocupă, de obicei, zeci de megabytes. Acest design eficient permite adaptoarelor să fie încărcate dinamic, stocate în memorie și schimbate după cum este necesar. Prin urmare, Apple Intelligence poate să se adapteze rapid la diferite sarcini, gestionând eficient memoria și asigurând reacția rapidă a sistemului.
În plus, Apple a dezvoltat o infrastructură robustă pentru a facilita adăugarea rapidă, retraining-ul, testarea și implementarea acestor adaptoare. Această infrastructură este esențială pentru a ține pasul cu actualizările modelului de bază sau ale datelor de antrenament, permițând îmbunătățiri fără întreruperi și introducerea de noi capabilități.
5.2 Optimizări
Optimizarea atât a latenței de inferență, cât și a eficienței energetice este crucială pentru a oferi o experiență utilizatorului fără întreruperi. Apple folosește mai multe tehnici avansate de optimizare pentru a se asigura că modelele fundamentale funcționează eficient pe dispozitive și în medii Private Cloud Compute.
Tehnici de Quantizare a Modelului
Pentru a adapta modelele AFM la bugetele de memorie restrânse ale dispozitivelor edge și pentru a minimiza costurile de inferență, Apple utilizează quantizarea modelului. Această tehnică reduce numărul efectiv de biți pe greutate, permițând o scădere semnificativă a utilizării memoriei fără a compromite substanțial calitatea modelului. Cercetările au indicat că modelele cuantizate la 4 biți pot menține niveluri de performanță comparabile cu omologii lor de 32/16 biți.
Metodele de quantizare de vârf ale Apple, combinate cu adaptoarele de recuperare a acurateței, permit quantizarea aproape fără pierderi, cu o medie de mai puțin de 4 biți pe greutate. Această abordare asigură că modelele cuantizate păstrează capabilitățile critice necesare pentru diverse funcționalități ale produsului. Adaptoarele de recuperare a acurateței sunt antrenate pentru a recupera orice calitate pierdută în timpul quantizării, permițând echipelor de aplicații să ajusteze eficient adaptoarele specifice pentru funcționalități.
Quantizarea cu Precizie Mixtă
Arhitectura încorporează conexiuni reziduale între blocurile de transformer, evidențiind că nu toate straturile au o importanță egală. Ca rezultat, unele straturi pot funcționa cu quantizare de 2 biți în loc de 4 biți, care este valoarea implicită. Această abordare cu precizie mixtă permite modelului AFM-on-device să atingă o compresie medie de aproximativ 3.5 biți pe greutate, menținând în același timp o calitate semnificativă a modelului.
Analiza Interactivă a Modelului
Pentru a rafina și mai mult arhitectura, Apple folosește Talaria, un instrument interactiv de analiză a latenței și puterii modelului. Acest instrument ajută la selectarea ratelor optime de biți pentru diferite operațiuni, asigurându-se că performanța modelului se aliniază cu experiența utilizatorului dorită.
5.3 Studiu de Caz: Rezumarea
O aplicație practică a modelului AFM-on-device este rolul său în alimentarea funcțiilor de rezumare pentru e-mailuri, mesaje și notificări. Deși modelul de bază demonstrează bune capabilități generale de rezumare, specificațiile și constrângerile specifice necesită adesea ajustări fine.
Pentru a îmbunătăți capacitatea de rezumare a modelului, Apple ajustează un adaptor LoRA deasupra modelului AFM-on-device cuantizat. Acest adaptor este inițializat din adaptorul de recuperare a acurateței, asigurându-se că folosește cunoștințele învățate anterior, în timp ce se specializează în sarcini de rezumare.
Amestecul de date de antrenament include rezumate sintetice generate de AFM-server, împreună cu seturi de date publice și date de la furnizori, toate fiind filtrate cu atenție pentru a asigura calitatea și conformitatea cu standardele de confidențialitate ale utilizatorilor. Filtrele bazate pe reguli și cele bazate pe model rafinează și mai mult datele, asigurându-se că procesul de ajustare fină produce rezumate de înaltă calitate care îndeplinesc specificațiile produsului.
Concluzie
Arhitectura Apple Intelligence reprezintă un avans semnificativ în AI, punând accent pe eficiență, adaptabilitate și design centrat pe utilizator. Prin integrarea adaptoarelor schimbabile în timpul execuției și aplicarea tehnicilor sofisticate de quantizare și optimizare, Apple a creat un model de bază care este nu doar puternic, ci și receptiv la nevoile diverse ale utilizatorilor săi. Angajamentul de a menține standarde înalte de calitate și eficiență subliniază dedicația Apple de a îmbunătăți experiența utilizatorului în întreaga sa ecologie de dispozitive.
Rezultate
Evaluări de Performanță
Modelele demonstrează o performanță puternică în diverse evaluări:
- AFM-on-device: Depășește modele open-source mai mari, cum ar fi Mistral-7B, în urmărirea instrucțiunilor și sarcini matematice.
- AFM-server: Realizează o performanță competitivă față de GPT-3.5 în capabilitățile generale.
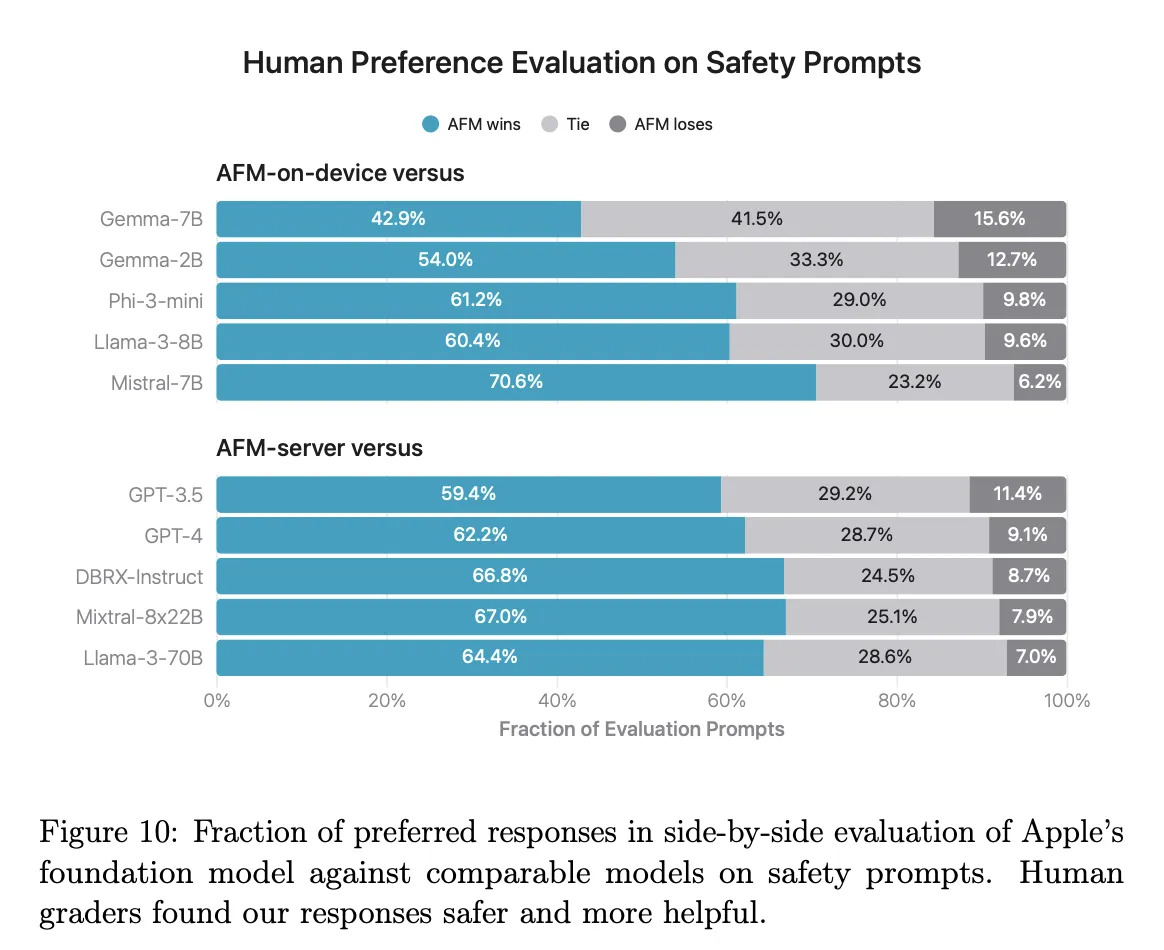
Siguranță și Responsabilitate
Ambele modele prezintă o performanță superioară în evaluările de siguranță comparativ cu modelele open-source și comerciale, subliniind angajamentul Apple față de AI responsabil.
Concluzie
Modelele de bază de limbaj ale Apple reprezintă un avans semnificativ în capabilitățile AI, fiind concepute pentru a alimenta funcții inteligente în dispozitivele Apple. Aceste modele sunt nu doar rapide și eficiente, ci și aliniate cu valorile Apple de confidențialitate și design centrat pe utilizator.
Pentru informații mai detaliate, vă rugăm să consultați lucrarea completă: Apple. “Apple Intelligence Foundation Language Models.” arXiv, 29 iul. 2024, arxiv.org/abs/2407.21075.
Detalii Extinse
Introducere
La Conferința Mondială a Dezvoltatorilor din 2024, Apple a introdus Apple Intelligence, un sistem de inteligență personală integrat profund în iOS 18, iPadOS 18 și macOS Sequoia. Apple Intelligence constă din mai multe modele generative extrem de capabile, care sunt rapide, eficiente, specializate pentru sarcinile zilnice ale utilizatorilor și pot să se adapteze dinamic în funcție de activitățile curente.
Pre-antrenament de Bază
Pre-antrenamentul de bază formează fundația modelelor de limbaj ale Apple. Datele utilizate acoperă diverse domenii pentru a asigura o învățare cuprinzătoare:
- Pagini Web: O parte semnificativă a setului de date, oferind structuri și contexte lingvistice diverse.
- Seturi de Date Licențiate: Date de înaltă calitate curate și licențiate specific pentru antrenament.
- Conținut de Cod și Matematic: Îmbunătățește capacitatea modelului de a înțelege și genera cod, precum și de a rezolva probleme matematice complexe.
- Seturi de Date Publice: Include seturi de date disponibile gratuit care sunt filtrate cu atenție pentru a menține calitatea.
Acest set de date diversificat asigură că modelul dezvoltă o înțelegere robustă capabilă să generalizeze pe diferite sarcini.
Continuarea Pre-training-ului
Pentru a îmbunătăți și mai mult capacitățile modelului, se efectuează continuarea pre-antrenamentului cu un amestec ajustat de date:
- Lungimi Mai Mari ale Secvențelor: Antrenamentul pe secvențe mai lungi permite modelului să înțeleagă și să genereze mai bine contexte extinse.
- Ajustarea Amestecului de Date: Ajustarea amestecului de surse de date îmbunătățește adaptabilitatea modelului la diverse sarcini.
Extinderea Contextului
Îndelungarea contextului este un pas crucial în îmbunătățirea performanței modelului în sarcinile care necesită înțelegerea și generarea de secvențe lungi. Prin antrenarea pe secvențe de până la 32k de tokeni, modelul devine capabil să gestioneze dialoguri extinse, documente lungi și alte sarcini care necesită un context amplu.
Ajustarea Supravegheată
Ajustarea supravegheată adaptează modelul la sarcini specifice prin furnizarea de date etichetate. Acest proces asigură că modelul nu numai că înțelege tiparele generale ale limbajului, dar excelează și în aplicații particulare, cum ar fi generarea de text, sumarizarea și altele.
Învățarea prin Întărire din Feedback-ul Uman (RLHF)
RLHF implică încorporarea feedback-ului uman în procesul de antrenament pentru a rafina rezultatele modelului. Acest proces iterativ ajută modelul să se alinieze mai aproape de preferințele și așteptările umane, îmbunătățind utilizabilitatea și fiabilitatea acestuia.
Comitetul de Învățare Iterativă (iTeC)
Tehnica iTeC implică un comitet de experți care revizuiesc și îmbunătățesc iterativ rezultatele modelului. Această abordare asigură că modelul beneficiază de perspective și expertiză diverse, ducând la o performanță mai rafinată și precisă.
Mirror Descent cu Estimarea Leave-One-Out (MDLOO)
MDLOO este o tehnică avansată de optimizare utilizată pentru a ajusta eficient parametrii modelului. Prin ajustarea iterativă a parametrilor pe baza estimării leave-one-out, această tehnică ajută la atingerea unei performanțe optime cu un overhead computațional minim.
Specializarea Folosind Adaptoare LoRA
Adaptoarele LoRA permit specializarea modelului pentru sarcini specifice în mod dinamic. Aceste adaptoare pot fi încărcate după cum este necesar, oferind flexibilitate și eficiență. Această abordare asigură că modelele pot gestiona o gamă largă de sarcini fără a necesita o retraining extinsă pentru fiecare nouă aplicație.
Optimizări pentru Eficiență
Pentru a face modelele eficiente pentru utilizarea pe dispozitive, se aplică mai multe optimizări:
- Quantizare: Reduce dimensiunea modelului și cerințele computaționale fără a afecta semnificativ performanța.
- Pruning: Elimină parametrii redundanți, sporind și mai mult eficiența.
Aceste optimizări asigură că modelele pot funcționa fără probleme pe dispozitive cu resurse computaționale limitate, oferind o performanță rapidă și receptivă.
Benchmark-uri de Performanță
Modelele au fost evaluate pe baza mai multor benchmark-uri pentru a le evalua performanța:
- Urmărirea Instrucțiunilor: AFM-on-device demonstrează o performanță superioară în urmărirea instrucțiunilor comparativ cu modele open-source mai mari.
- Sarcini Matematice: Modelul excelează în rezolvarea problemelor matematice, demonstrând capacități avansate de raționare.
- Capabilități Generale: AFM-server performează competitiv față de GPT-3.5, evidențiind versatilitatea și puterea sa în sarcinile generale de limbaj.
Siguranță și Responsabilitate
Evaluările de siguranță indică faptul că modelele Apple depășesc atât modelele open-source, cât și cele comerciale în respectarea liniilor directoare de siguranță. Această concentrare asupra AI-ului responsabil asigură că modelele oferă rezultate fiabile și etice, aliniindu-se valorilor Apple.
Concluzie
Modelele de limbaj fundamentale Apple reprezintă un salt semnificativ înainte în capabilitățile AI. Aceste modele sunt concepute pentru a fi rapide, eficiente și extrem de capabile, alimentând o gamă largă de funcții inteligente pe dispozitivele Apple. Prin concentrarea asupra eficienței, acurateței și responsabilității, Apple stabilește un nou standard pentru AI în tehnologia de consum.
Pentru detalii cuprinzătoare, consultați lucrarea completă: Apple. “Apple Intelligence Foundation Language Models.” arXiv, 29 iul. 2024, arxiv.org/abs/2407.21075.
Bot Personalizat Gratuit ChatGPT cu BotGPT
Pentru a valorifica pe deplin potențialul LLM-urilor pentru nevoile dumneavoastră specifice, luați în considerare crearea unui chatbot personalizat adaptat la datele și cerințele dumneavoastră. Explorați BotGPT pentru a descoperi cum puteți profita de tehnologia avansată AI pentru a construi soluții personalizate și a vă îmbunătăți proiectele de afaceri sau personale. Prin îmbrățișarea capabilităților BotGPT, puteți rămâne cu un pas înainte în peisajul în evoluție al AI-ului și debloca noi oportunități de inovație și interacțiune.
Descoperiți puterea asistentului nostru virtual versatil, alimentat de tehnologia de vârf GPT, adaptat pentru a satisface nevoile dumneavoastră specifice.
Funcții
-
Îmbunătățiți Productivitatea: Transformați fluxul de lucru cu eficiența BotGPT. Începeți
-
Integrare Seamless: Integrați cu ușurință BotGPT în aplicațiile dumneavoastră. Aflați Mai Multe
-
Optimizați Crearea de Conținut: Creșteți procesul de creare și editare a conținutului cu BotGPT. Încercați Acum
-
Asistență Virtuală 24/7: Accesați BotGPT oricând, oriunde pentru suport instantaneu. Explorați Aici
-
Soluții Personalizabile: Adaptați BotGPT pentru a se potrivi perfect cerințelor afacerii dumneavoastră. Personalizați Acum
-
Informații Bazate pe AI: Descoperiți informații valoroase cu capabilitățile avansate ale BotGPT. Descoperiți Mai Multe
-
Deblocați Funcții Premium: Faceți upgrade la BotGPT pentru funcții exclusive. Faceți Upgrade Astăzi
Despre BotGPT
BotGPT este un chatbot puternic alimentat de tehnologia avansată GPT, conceput pentru integrare seamless pe diverse platforme. Îmbunătățiți productivitatea și creativitatea cu asistența virtuală inteligentă oferită de BotGPT.
Conectați-vă cu noi la BotGPT și descoperiți viitorul asistenței virtuale.