
Transformer Model: Attention Is All You Need
Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT FreeIn the realm of natural language processing and machine translation, the Transformer model has emerged as a pivotal innovation, significantly advancing the state-of-the-art in various tasks. Originally proposed by Vaswani et al., in their seminal paper titled “Attention Is All You Need,” this model introduces a novel architecture that dispenses with traditional recurrent neural networks (RNNs) and convolutional layers, relying solely on attention mechanisms.
Introduction
Traditionally, sequence modeling tasks such as language translation heavily relied on RNNs and their variants due to their ability to handle sequential data. However, the sequential nature of RNNs posed challenges in terms of parallelization and computational efficiency, especially with longer sequences. The Transformer model addresses these limitations by leveraging self-attention mechanisms.
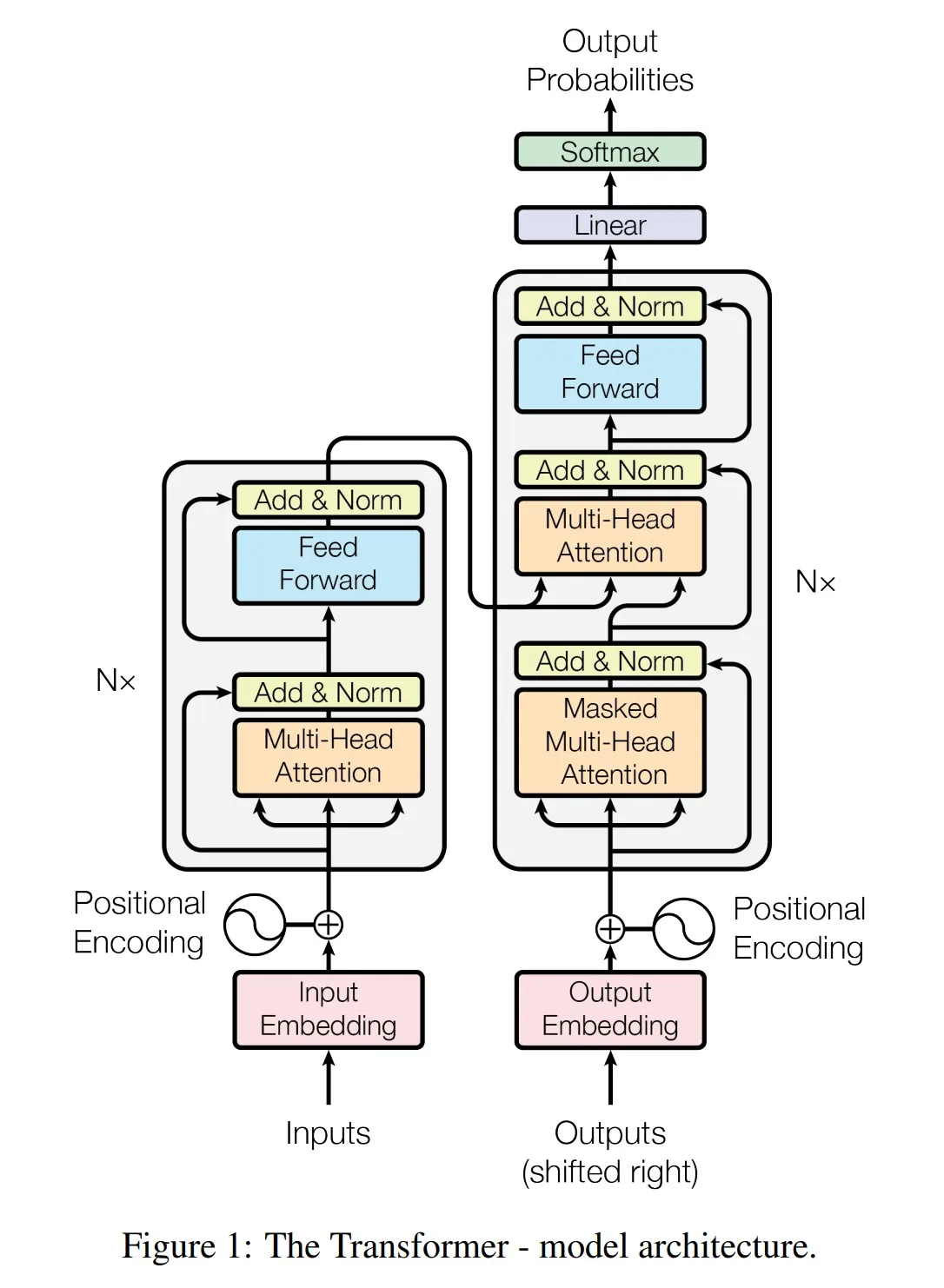
Model Architecture
Self-Attention Mechanism
At the heart of the Transformer lies the self-attention mechanism, also known as intra-attention. Unlike RNNs that process inputs sequentially, self-attention allows the model to weigh the significance of each word in relation to every other word in the input sequence simultaneously. This parallelization not only improves computational efficiency but also enhances the model’s ability to capture long-range dependencies within sequences.
Multi-Head Attention
To further enhance its representational power, the Transformer employs multi-head attention. This mechanism enables the model to jointly attend to information from different representation subspaces at different positions. Each attention head independently processes the input through linear projections of queries, keys, and values, which are subsequently concatenated and linearly transformed again.
Position-wise Feed-Forward Networks
In addition to attention mechanisms, each layer of the Transformer includes position-wise feed-forward networks. These networks apply two linear transformations with a ReLU activation function, providing additional flexibility and expressive power to the model.
Why Choose Self-Attention?
The decision to replace RNNs with self-attention was motivated by several advantages:
-
Computational Efficiency: Self-attention layers require O(n^2 * d) computational complexity per layer, where n is the sequence length and d is the representation dimensionality. This is often more efficient than the O(n * d^2) complexity of RNNs for typical sequence representations.
-
Parallelization: By allowing parallel computation across sequence positions, the Transformer model can process inputs more efficiently, especially beneficial for tasks involving long sequences.
-
Capturing Long-Range Dependencies: Learning dependencies between distant positions is crucial for tasks like machine translation. Self-attention’s ability to connect all positions with a constant number of operations facilitates the learning of such dependencies more effectively than traditional architectures.
Training and Results
Training Regime
The Transformer was trained on large-scale datasets like WMT 2014 English-German and English-French using byte-pair encoding. Training batches were organized by sequence length to optimize performance on NVIDIA P100 GPUs, with significant improvements in computational efficiency reported compared to previous state-of-the-art models.
Performance
The Transformer achieved remarkable results in terms of translation quality, outperforming established models like ByteNet and ConvS2S. Even the base model surpassed all previously published models and ensembles, establishing new benchmarks in BLEU scores for translation tasks.
Conclusion
The Transformer model represents a paradigm shift in sequence modeling and machine translation, demonstrating that attention mechanisms can effectively replace traditional sequential processing approaches like RNNs. Its ability to parallelize computation and capture long-range dependencies has set new standards in the field, promising further innovations in natural language processing and beyond.
For more detailed insights into the Transformer model and its applications, you can access the original paper “Attention Is All You Need”.
This blog post provides a concise overview of the Transformer model, emphasizing its architecture, advantages over traditional models, and its impact on machine translation tasks.