
DeepSeek-R1 by DeepSeek AI: A New Frontier in Language Modeling

Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT Free1. Introduction
We present the DeepSeek-R1 series, including the first-generation reasoning models: DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero was developed through large-scale reinforcement learning (RL) without the preliminary step of supervised fine-tuning (SFT). This model demonstrated remarkable performance in reasoning tasks, with RL enabling it to naturally discover powerful and interesting reasoning behaviors. Despite its success, DeepSeek-R1-Zero faced challenges, including endless repetition, poor readability, and language mixing.
To address these challenges and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates cold-start data prior to the RL phase. DeepSeek-R1 achieves performance comparable to OpenAI-o1 in areas such as math, code, and reasoning tasks. In our effort to support the research community, we are open-sourcing both DeepSeek-R1-Zero and DeepSeek-R1, along with six distilled models derived from DeepSeek-R1 based on the Llama and Qwen architectures. Notably, DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across a range of benchmarks, setting new state-of-the-art results for dense models.
Note: Before running the DeepSeek-R1 series models locally, we recommend reviewing the Usage Recommendations section.
2. Model Summary
Post-Training: Large-Scale Reinforcement Learning on the Base Model
Our approach directly applies reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as an initial step. This strategy allows the model to explore chain-of-thought (CoT) reasoning for solving complex problems, culminating in the creation of DeepSeek-R1-Zero. The model demonstrates self-verification, reflection, and the ability to generate long CoTs, marking a key milestone for the research community. This is the first open research validating that the reasoning capabilities of large language models (LLMs) can be incentivized solely through RL, without the need for SFT. This breakthrough opens new possibilities for advancements in AI reasoning.
To further improve reasoning, we introduce the pipeline for developing DeepSeek-R1, which consists of two RL stages to refine reasoning patterns and align with human preferences, followed by two SFT stages to provide foundational reasoning and non-reasoning capabilities. We believe this pipeline will significantly benefit the AI industry by producing better models.
Distillation: Smaller Models Can Be Powerful Too
We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, leading to superior performance compared to smaller models trained solely with RL. The open-sourced DeepSeek-R1, along with its API, will help the research community develop more efficient distilled models in the future.
Using reasoning data generated by DeepSeek-R1, we fine-tuned several smaller dense models commonly used in the research community. Evaluation results reveal that the distilled smaller models excel on a variety of benchmarks. We are open-sourcing distilled checkpoints for models with parameter sizes of 1.5B, 7B, 8B, 14B, 32B, and 70B, based on Qwen2.5 and Llama3 architectures.
3. Model Downloads
DeepSeek-R1 Models
| Model | #Total Params | #Activated Params | Context Length | Download Link |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | HuggingFace |
Both DeepSeek-R1-Zero and DeepSeek-R1 are based on DeepSeek-V3-Base. For further details regarding the model architecture, please refer to the DeepSeek-V3 repository.
DeepSeek-R1-Distill Models
| Model | Base Model | Download Link |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | HuggingFace |
The DeepSeek-R1-Distill models are fine-tuned based on open-source models and use samples generated by DeepSeek-R1. We have made slight adjustments to their configurations and tokenizers, so please use our settings to run these models.
4. Evaluation Results
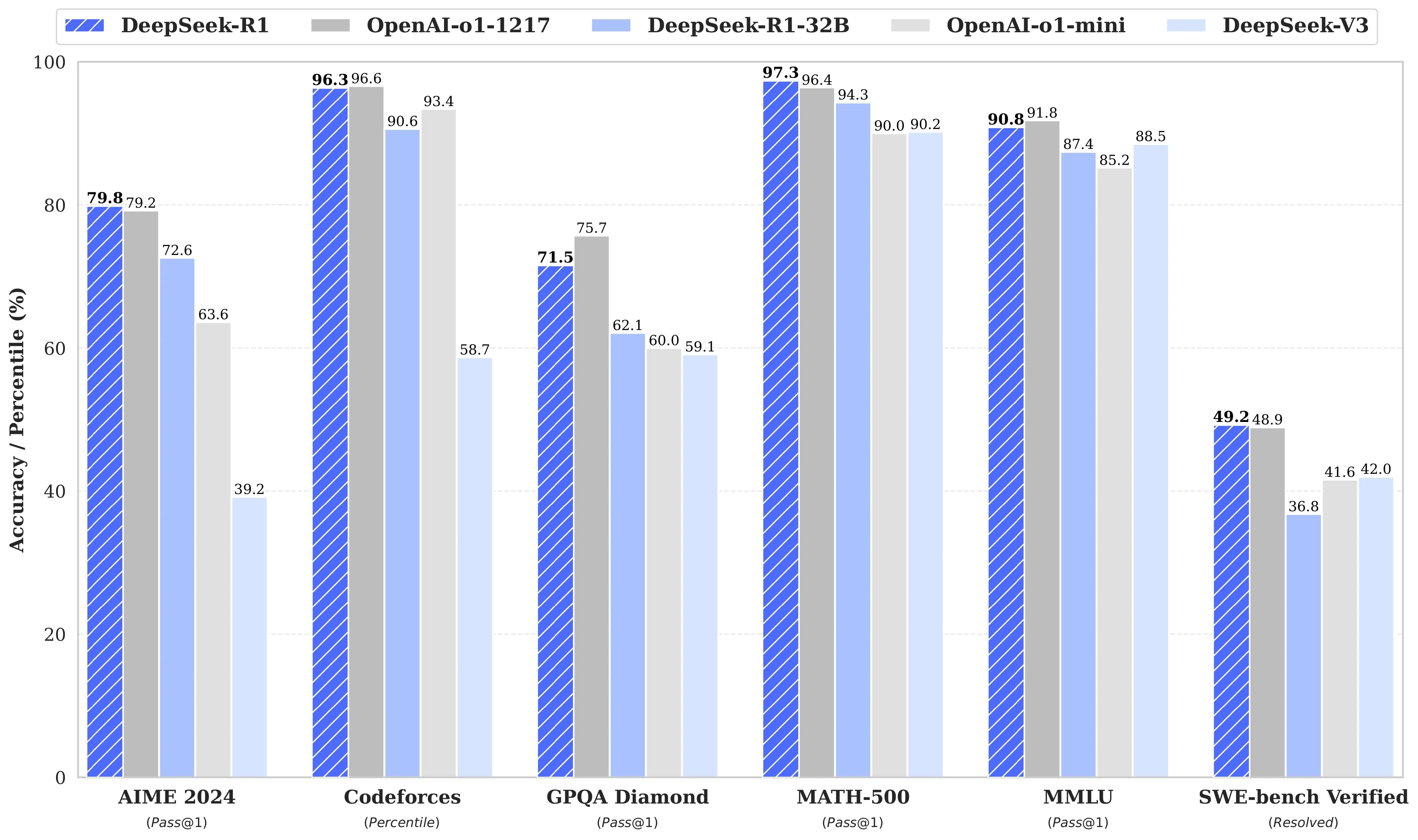
DeepSeek-R1 Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of 0.6, a top-p value of 0.95, and generate 64 responses per query to estimate pass@1.
Benchmarks (English)
| Category | Metric | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|---|
| MMLU | Pass@1 | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| DROP | 3-shot F1 | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 |
| GPQA | Diamond Pass@1 | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 |
| SimpleQA | Correct | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 |
Benchmarks (Math)
| Category | Metric | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|---|
| AIME 2024 | Pass@1 | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 | Pass@1 | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 |
Distilled Model Evaluation
| Model | AIME 2024 pass@1 | MATH-500 pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 74.6 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 78.3 | 38.9 | 717 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 83.9 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 92.8 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 94.3 | 57.2 | 1691 |
DeepSeek-V3
DeepSeek-V3 by DeepSeek AI represents a significant leap forward in the evolution of language models. By harnessing an innovative Mixture-of-Experts (MoE) architecture and a suite of advanced training methodologies, DeepSeek-V3 sets a new benchmark for performance, efficiency, and scalability in natural language processing.
Introduction
DeepSeek-V3 is designed to push the boundaries of language understanding and generation. With a staggering 671B total parameters and 37B activated parameters per token, the model integrates:
- Multi-head Latent Attention (MLA): Enabling efficient context handling.
- DeepSeekMoE Architecture: Building on proven techniques from DeepSeek-V2 while introducing a revolutionary auxiliary-loss-free load balancing strategy.
- Multi-Token Prediction (MTP): A novel training objective that not only boosts performance but also accelerates inference via speculative decoding.
The model has been pre-trained on 14.8 trillion high-quality tokens using an FP8 mixed precision framework, ensuring both training efficiency and computational stability. Subsequent fine-tuning phases, including Supervised Fine-Tuning and Reinforcement Learning, further enhance its reasoning and conversational abilities, distilled from the long Chain-of-Thought (CoT) capabilities of DeepSeek-R1.
Model Summary
Architecture & Innovations
-
Auxiliary-Loss-Free Load Balancing:
Unlike conventional methods that risk performance degradation, our new strategy effectively balances computational load without incurring additional losses. -
Multi-Token Prediction (MTP):
This objective not only enhances the model’s performance across diverse tasks but also supports speculative decoding, which significantly accelerates inference. -
Efficient Pre-Training:
Leveraging FP8 mixed precision training for the first time at this scale, we have overcome traditional communication bottlenecks in cross-node MoE training—realizing nearly full computation-communication overlap. This breakthrough enables us to scale up the model efficiently and cost-effectively. -
Post-Training Distillation:
Integrating reasoning capabilities from the DeepSeek-R1 series through a sophisticated knowledge distillation pipeline, DeepSeek-V3 achieves superior performance without compromising on output style or length.
Training Efficiency
-
Training Cost:
The entire training process required only 2.788M H800 GPU hours, a testament to the remarkable efficiency of our training framework. -
Stability:
Throughout training, DeepSeek-V3 maintained stability without any irrecoverable loss spikes or rollbacks.
Model Downloads
| Model | Total Params | Activated Params | Context Length | Download |
|---|---|---|---|---|
| DeepSeek-V3-Base | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-V3 | 671B | 37B | 128K | 🤗 HuggingFace |
Note: The HuggingFace model size totals 685B, which includes 671B for the Main Model and 14B for the Multi-Token Prediction (MTP) module.
Developers looking for detailed configuration information can refer to the accompanying README_WEIGHTS.md. Community contributions and feedback on the ongoing development of the MTP module are highly encouraged.
Evaluation Results
Base Model Benchmarks
DeepSeek-V3 outperforms its predecessors and several dense models in multiple standard benchmarks. Highlights include:
-
Mathematical and Code Proficiency:
Exceptional performance on tasks like GSM8K, MATH, and code evaluation benchmarks (HumanEval, MBPP) that showcase its robust reasoning and problem-solving abilities. -
Comprehensive English and Multilingual Competence:
Achieving leading scores in benchmarks such as BBH, MMLU, and CLUEWSC, DeepSeek-V3 consistently demonstrates a well-rounded linguistic capability.
Sample Benchmark Results
| Benchmark (Metric) | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 |
|---|---|---|---|---|
| BBH (EM, 3-shot) | 78.8 | 79.8 | 82.9 | 87.5 |
| MMLU (Acc., 5-shot) | 78.4 | 85.0 | 84.4 | 87.1 |
| DROP (F1, 3-shot) | 80.4 | 80.6 | 86.0 | 89.0 |
Chat Model Performance
In conversational AI benchmarks, DeepSeek-V3 remains competitive with both open-source and leading closed-source models. Its ability to handle extended conversations with context windows up to 128K tokens sets it apart in long-form dialogue generation.
Open-Ended Generation
| Evaluation | DeepSeek-V3 |
|---|---|
| Arena-Hard | 85.5 |
| AlpacaEval 2.0 | 70.0 |
Chat Website & API Platform
Engage with DeepSeek-V3 directly:
-
Chat Interface:
Visit chat.deepseek.com to start a conversation with DeepSeek-V3. -
API Access:
Utilize our OpenAI-compatible API at platform.deepseek.com for seamless integration into your applications.
DeepSeek Explained: Everything You Need to Know
In the world of AI, there has been a prevailing notion that developing leading-edge large language models requires significant technical and financial resources. That’s one of the main reasons why the U.S. government pledged to support the $500 billion Stargate Project announced by President Donald Trump.
But Chinese AI development firm DeepSeek has disrupted that notion. On Jan. 20, 2025, DeepSeek released its R1 LLM at a fraction of the cost that other vendors incurred in their own developments. DeepSeek is also providing its R1 models under an open-source license, enabling free use.
Within days of its release, the DeepSeek AI assistant — a mobile app that provides a chatbot interface for DeepSeek R1 — hit the top of Apple’s App Store chart, outranking OpenAI’s ChatGPT mobile app. The meteoric rise of DeepSeek in terms of usage and popularity triggered a stock market sell-off on Jan. 27, 2025, as investors cast doubt on the value of large AI vendors based in the U.S., including Nvidia. Microsoft, Meta Platforms, Oracle, Broadcom, and other tech giants also saw significant drops as investors reassessed AI valuations.
What is DeepSeek?
DeepSeek is an AI development firm based in Hangzhou, China. The company was founded by Liang Wenfeng, a graduate of Zhejiang University, in May 2023. Wenfeng also co-founded High-Flyer, a China-based quantitative hedge fund that owns DeepSeek. Currently, DeepSeek operates as an independent AI research lab under the umbrella of High-Flyer. The full amount of funding and the valuation of DeepSeek have not been publicly disclosed.
DeepSeek focuses on developing open-source LLMs. The company’s first model was released in November 2023. The company has iterated multiple times on its core LLM and has built out several different variations. However, it wasn’t until January 2025 after the release of its R1 reasoning model that the company became globally famous.
The company provides multiple services for its models, including a web interface, mobile application, and API access.
OpenAI vs. DeepSeek
DeepSeek represents the latest challenge to OpenAI, which established itself as an industry leader with the debut of ChatGPT in 2022. OpenAI has helped push the generative AI industry forward with its GPT family of models, as well as its o1 class of reasoning models.
While the two companies are both developing generative AI LLMs, they have different approaches.
| OpenAI | DeepSeek | |
|---|---|---|
| Founding Year | 2015 | 2023 |
| Headquarters | San Francisco, Calif. | Hangzhou, China |
| Development Focus | Broad AI capabilities | Efficient, open-source models |
| Key Models | GPT-4o, o1 | DeepSeek-V3, DeepSeek-R1 |
| Specialized Models | Dall-E (image generation), Whisper (speech recognition) | DeepSeek Coder (coding), Janus Pro (vision model) |
| API Pricing (per million tokens) | o1: | DeepSeek-R1: |
| Open Source Policy | Limited | Mostly open-source |
| Training Approach | Supervised and instruction-based fine-tuning | Reinforcement learning |
| Development Cost | Hundreds of millions of dollars for o1 (estimated) | Less than $6 million for DeepSeek-R1, according to the company |
Training Innovations in DeepSeek
DeepSeek uses a different approach to train its R1 models than what is used by OpenAI. The training involved less time, fewer AI accelerators, and lower costs to develop. DeepSeek’s aim is to achieve artificial general intelligence, and the company’s advancements in reasoning capabilities represent significant progress in AI development.
In a research paper, DeepSeek outlines the multiple innovations it developed as part of the R1 model, including the following:
- Reinforcement Learning: DeepSeek used a large-scale reinforcement learning approach focused on reasoning tasks.
- Reward Engineering: Researchers developed a rule-based reward system for the model that outperforms neural reward models commonly used.
- Distillation: Using efficient knowledge transfer techniques, DeepSeek researchers successfully compressed capabilities into models as small as 1.5 billion parameters.
- Emergent Behavior Network: DeepSeek’s emergent behavior innovation is the discovery that complex reasoning patterns can develop naturally through reinforcement learning without explicitly programming them.
DeepSeek Large Language Models
Since the company was created in 2023, DeepSeek has released a series of generative AI models. With each new generation, the company has worked to advance both the capabilities and performance of its models:
- DeepSeek Coder: Released in November 2023, this is the company’s first open-source model designed specifically for coding-related tasks.
- DeepSeek LLM: Released in December 2023, this is the first version of the company’s general-purpose model.
- DeepSeek-V2: Released in May 2024, this is the second version of the company’s LLM, focusing on strong performance and lower training costs.
- DeepSeek-Coder-V2: Released in July 2024, this is a 236 billion-parameter model offering a context window of 128,000 tokens, designed for complex coding challenges.
- DeepSeek-V3: Released in December 2024, DeepSeek-V3 uses a mixture-of-experts architecture, capable of handling a range of tasks. The model has 671 billion parameters with a context length of 128,000.
- DeepSeek-R1: Released in January 2025, this model is based on DeepSeek-V3 and is focused on advanced reasoning tasks directly competing with OpenAI’s o1 model in performance, while maintaining a significantly lower cost structure. Like DeepSeek-V3, the model has 671 billion parameters with a context length of 128,000.
- Janus-Pro-7B: Released in January 2025, Janus-Pro-7B is a vision model that can understand and generate images.
Why It Is Raising Alarms in the U.S.
The release of DeepSeek-R1 has raised alarms in the U.S., triggering concerns and a stock market sell-off in tech stocks. On Monday, Jan. 27, 2025, the Nasdaq Composite dropped by 3.4% at market opening, with Nvidia declining by 17% and losing approximately $600 billion in market capitalization.
DeepSeek is raising alarms in the U.S. for several reasons, including the following:
- Cost Disruption: DeepSeek claims to have developed its R1 model for less than $6 million. The low-cost development threatens the business model of U.S. tech companies that have invested billions in AI. DeepSeek is also cheaper for users than OpenAI.
- Technical Achievement Despite Restrictions: The export of the highest-performance AI accelerator and GPU chips from the U.S. is restricted to China. Yet, despite that, DeepSeek has demonstrated that leading-edge AI development is possible without access to the most advanced U.S. technology.
- Business Model Threat: In contrast with OpenAI, which is proprietary technology, DeepSeek is open-source and free, challenging the revenue model of U.S. companies charging monthly fees for AI services.
- Geopolitical Concerns: Being based in China, DeepSeek challenges U.S. technological dominance in AI. Tech investor Marc Andreessen called it AI’s “Sputnik moment,” comparing it to the Soviet Union’s space race breakthrough in the 1950s.
DeepSeek Cyberattack
DeepSeek’s popularity has not gone unnoticed by cyberattackers.
On Jan. 27, 2025, DeepSeek reported large-scale malicious attacks on its services, forcing the company to temporarily limit new user registrations. The timing of the attack coincided with DeepSeek’s AI assistant app overtaking ChatGPT as the top downloaded app on the Apple App Store.
Despite the attack, DeepSeek maintained service for existing users. The issue extended into Jan. 28, when the company reported it had identified the issue and deployed a fix.
DeepSeek has not specified the exact nature of the attack, though widespread speculation from public reports indicated it was some form of DDoS attack targeting its API and web chat platform.
How to Run Locally
Ollama
DeepSeek-R1
Run the first-generation DeepSeek model:
ollama run deepseek-r1:671bDistilled Models
The reasoning patterns of larger models have been distilled into smaller models for better performance.
DeepSeek-R1-Distill-Qwen-1.5B
Run the distilled DeepSeek-R1 model with 1.5B parameters:
ollama run deepseek-r1:1.5bDeepSeek-R1-Distill-Qwen-7B
Run the distilled DeepSeek-R1 model with 7B parameters:
ollama run deepseek-r1:7bDeepSeek-R1-Distill-Llama-8B
Run the distilled DeepSeek-R1 model with Llama-8B parameters:
ollama run deepseek-r1:8bDeepSeek-R1-Distill-Qwen-14B
Run the distilled DeepSeek-R1 model with 14B parameters:
ollama run deepseek-r1:14bDeepSeek-R1-Distill-Qwen-32B
Run the distilled DeepSeek-R1 model with 32B parameters:
ollama run deepseek-r1:32bDeepSeek-R1-Distill-Llama-70B
Run the distilled DeepSeek-R1 model with Llama-70B parameters:
ollama run deepseek-r1:70bDeepSeek-V3 offers flexible deployment options for local and cloud environments through a range of open-source frameworks and hardware solutions.
DeepSeek-Infer Demo
- Clone the Repository:
git clone https://github.com/deepseek-ai/DeepSeek-V3.git- Install Dependencies:
# Installation and Setup Guide for DeepSeek-V3
## Install Dependencies:```bashcd DeepSeek-V3/inferencepip install -r requirements.txt-
Download and Prepare Model Weights: Place the downloaded weights in your designated folder.
-
Convert Weights to HuggingFace Format:
python convert.py --hf-ckpt-path /path/to/DeepSeek-V3 --save-path /path/to/DeepSeek-V3-Demo --n-experts 256 --model-parallel 16- Run the Inference Demo:
torchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addtorchrun --nnodes 2 --nproc-per-node 8 generate.py --node-rank $RANK --master-addr $ADDR --ckpt-path /path/to/DeepSeek-V3-Demo --config configs/config_671B.json --input-file $FILE