
Training DeepSeek-R1: The Math Behind Group Relative Policy Optimization (GRPO)

Training DeepSeek-R1: Understanding Group Relative Policy Optimization (GRPO)
Introduction
Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human values. Traditional approaches such as Proximal Policy Optimization (PPO) may suffer from issues like reward hacking and high variance. Group Relative Policy Optimization (GRPO) addresses these challenges by replacing absolute rewards with relative comparisons within groups of responses, thereby reducing variance and improving stability. In this article, we explain the mathematics behind GRPO and walk through a detailed, step-by-step example that demonstrates how the method operates in a realistic training scenario.
What is GRPO?
GRPO is a variant of PPO that eliminates the need for a separate critic network. Instead of estimating advantages using a value function, GRPO computes a group-relative advantage by comparing the reward of each response to the average reward in its group. The main components of the approach are:
- Grouping Responses: Responses to the same prompt are grouped together.
- Relative Advantage Calculation: The advantage of a response is determined by subtracting the group mean and dividing by the group standard deviation.
- Clipped Objective: As in PPO, the method uses a clipped surrogate loss to constrain updates, while a KL divergence penalty ensures that the updated policy does not deviate excessively from the reference.
The Hugging Face open‑r1 repository :contentReference[oaicite:2]{index="2"} provides an implementation that exemplifies these ideas, and further details can be found in the Medium article :contentReference[oaicite:3]{index="3"} .
GRPO Objective Function
For a given group
-
Group Mean and Standard Deviation:
-
Relative Advantage:
-
Clipped Surrogate Loss:
The policy update then maximizes the following loss:
where
A Step-by-Step Simple Math Example
The following example breaks down the GRPO process for a concrete query using multiple responses. It illustrates how rewards, relative advantages, and policy updates are computed.
Step 1: Start with a Query
Pick a query
Example Query:
“What is the sum of 8 + 5?”
Step 2: Generate a Group of Responses
For the query, the model generates a group of
Example Responses:
: “The answer is 13.” : “Thirteen.” : “It’s 12.” : “The sum is 13.”
Step 3: Calculate Rewards for Each Response
Rewards quantify the quality of the response based on multiple criteria such as accuracy, format, and language consistency.
Types of Rewards in GRPO:
- Accuracy Rewards: Correctness of the answer.
- Format Rewards: Adherence to a prescribed structure (e.g., including a reasoning section in
<think>tags). - Language Consistency Rewards: Coherent use of language without mixing styles.
Assigning Rewards (Example Values):
(correct and well-formatted) (correct but less formal) (incorrect answer) (correct and well-formatted)
Step 4: Compare Responses (Group Advantage Calculation)
Compute the group statistics for the four responses:
-
Group Mean (
): -
Group Standard Deviation (
): - Squared differences:
- For
: - For
: - For
: - For
:
- For
- Variance:
- Standard deviation:
- Squared differences:
-
Calculate Relative Advantage for Each Response:
- For
: - For
: - For
: - For
:
- For
Step 5: Policy Update via the Clipped Surrogate Objective
For each response, the model computes the ratio:
This ratio is then multiplied by the corresponding relative advantage
For instance, if
Benefits of This Approach
- Reduced Variance:
Normalizing within groups ensures that noisy absolute rewards do not mislead the update. - Resilience to Reward Hacking:
The model focuses on relative performance rather than absolute scores. - Simplified Architecture:
Without the need for an extra critic network, training becomes both faster and less memory intensive. - Stable Policy Updates:
The clipping mechanism, in combination with a KL divergence penalty, prevents excessive updates and helps maintain stability.
GRPO Results in DeepSeek-R1
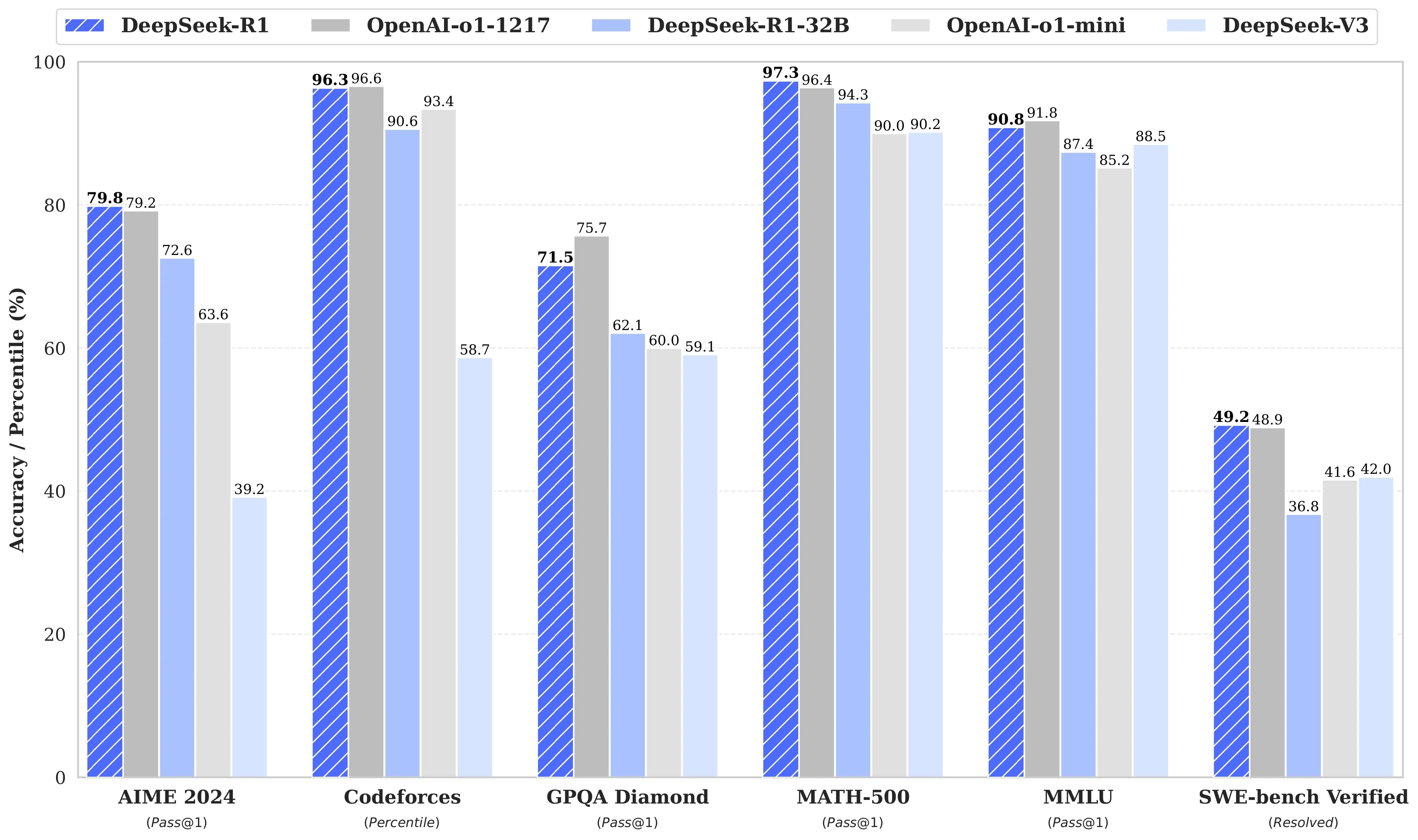
Reproducing DeepSeek-R1 Results
Using DeepSeek-R1 tech report as a starting point, we can reproduce the DeepSeek-R1 benchmark results which can roughly be broken down into three main steps:
- Step 1: replicate the R1-Distill models by distilling a high-quality corpus from DeepSeek-R1.
- Step 2: replicate the pure RL pipeline that DeepSeek used to create R1-Zero. This will likely involve curating new, large-scale datasets for math, reasoning, and code.
- Step 3: show we can go from base model to RL-tuned via multi-stage training.
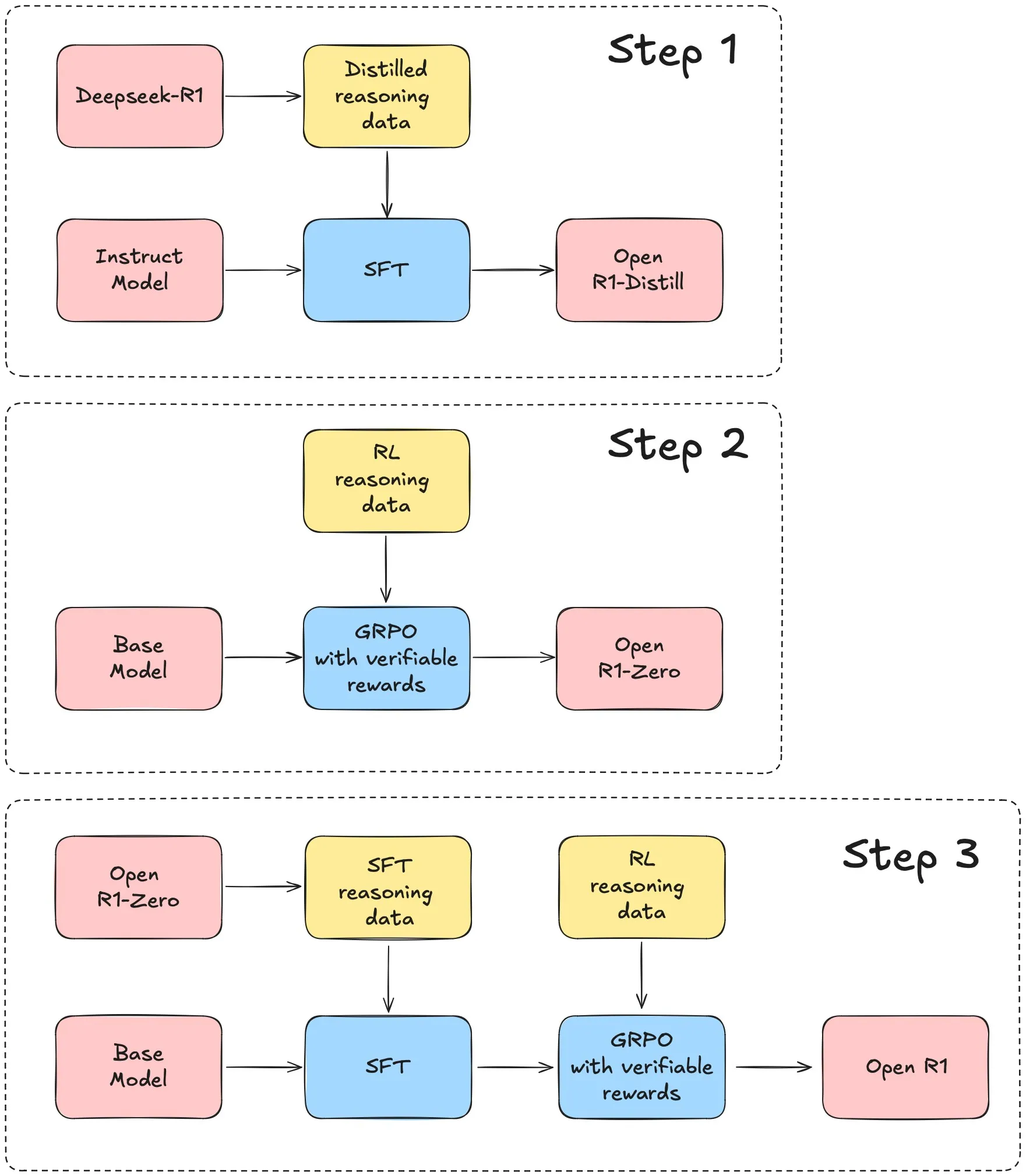
Comparison of GRPO and PPO
Reinforcement learning methods play a critical role in aligning large language models with human preferences. Two popular methods in this area are Proximal Policy Optimization (PPO) and its variant, Group Relative Policy Optimization (GRPO). While both are policy gradient methods that use a clipped surrogate objective to stabilize training, they differ in key aspects of their advantage estimation and computational requirements.
Proximal Policy Optimization (PPO)
PPO is widely used in reinforcement learning for its stability and efficiency. Its main components include:
-
Policy Network and Critic (Value Function):
PPO uses two networks:- The policy network (\pi_\theta) (the agent that generates actions), and
- A separate value function (V(s)) (the critic) that estimates the expected cumulative reward from a given state.
-
Advantage Estimation:
PPO computes an advantage function by subtracting the critic’s value estimate from the observed cumulative reward. In mathematical form, for a state (s) and action (a):Techniques such as Generalized Advantage Estimation (GAE) are typically used to balance bias and variance.
-
Clipped Surrogate Objective:
To ensure that policy updates are not too large, PPO maximizes a clipped objective:Additionally, a KL divergence penalty term is often included to keep the updated policy close to a reference policy.
Group Relative Policy Optimization (GRPO)
GRPO is a variant of PPO that introduces several innovations aimed at reducing computational overhead:
-
Elimination of the Critic Network:
Instead of training a separate value function to estimate the baseline for advantage calculation, GRPO estimates the baseline from a group of responses. For each prompt, it samples a group of responses ({r_1, r_2, \dots, r_G}) from the current policy. -
Group-Relative Advantage Estimation:
GRPO computes the advantage of each response by normalizing its reward relative to the group’s mean and standard deviation. For a response (i) with reward (r_i), the advantage is calculated as:where
This approach provides a relative (or standard score) measure of performance without a separate critic model.
-
Clipped Objective and KL Penalty:
Similar to PPO, GRPO uses a clipped surrogate loss. However, because the advantage is computed relative to the group, GRPO can forgo additional exploration bonuses (e.g., entropy) while still maintaining stable updates. The GRPO objective is given by:Here, the KL divergence penalty ensures the updated policy does not diverge excessively from the reference.
Key Differences
| Aspect | PPO | GRPO |
|---|---|---|
| Advantage Estimation | Uses a separate critic network to estimate (V(s)) and compute advantage (A(s, a) = Q(s, a) - V(s)). | Estimates advantage directly from group rewards by normalizing each reward relative to the group’s mean and standard deviation. |
| Network Complexity | Requires two networks (policy and critic), which increases memory and computational cost. | Eliminates the critic, reducing both memory usage and computational overhead. |
| Objective Function | Clipped surrogate objective with additional entropy bonus and KL penalty. | Uses a similar clipped objective and KL penalty, but without an entropy bonus, as group sampling encourages exploration. |
| Computational Efficiency | More computationally intensive due to critic evaluation. | More efficient, making it better suited for large-scale models where resources are at a premium. |
Conclusion
Both PPO and GRPO aim to stabilize policy updates through a clipped surrogate objective and KL divergence penalties. The key innovation in GRPO is its use of group-relative advantage estimation, which eliminates the need for a separate critic network. This simplification reduces computational overhead and memory usage while still providing effective advantage estimation for reinforcement learning. Such improvements are particularly valuable when training large language models (such as DeepSeek‑R1) where resource efficiency is critical.
By understanding these differences, researchers and practitioners can choose the approach that best fits their computational constraints and task requirements.
Group Relative Policy Optimization (GRPO) offers a streamlined yet robust method for training LLMs. By comparing responses in a group and computing relative advantages, GRPO minimizes variance and avoids pitfalls such as reward hacking—all while reducing computational costs. This article provided both a theoretical overview and a detailed, step-by-step math example, demonstrating how a query is processed through generating responses, assigning rewards, computing group-relative advantages, and finally using these values in a constrained policy update.
References: