
Understanding Low-Rank Adaptation (LoRA): Revolutionizing Fine-Tuning for Large Language Models
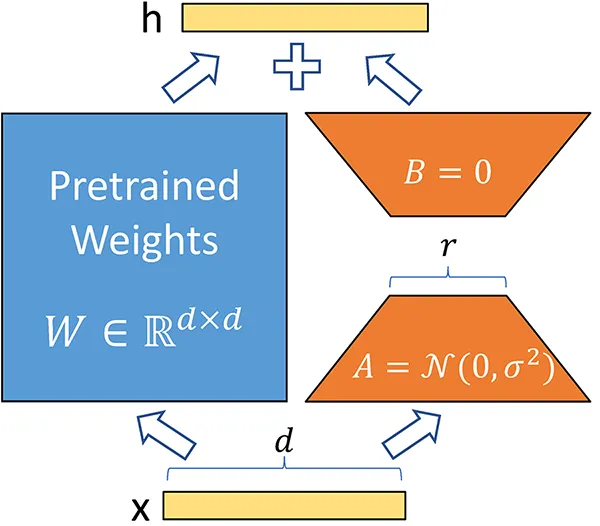
This article explores Low-Rank Adaptation (LoRA), a transformative technique for efficiently fine-tuning large language models (LLMs) like GPT-4 and Stable Diffusion. By reducing the computational burden of adapting these models, LoRA enables faster and more cost-effective training processes. We will cover its principles, advantages, and practical applications, as well as provide a hands-on implementation guide using Python libraries.
