
Apple Intelligence Foundation Language Models

Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT FreeThis document outlines Apple’s foundation language models, meticulously crafted to enhance the Apple Intelligence features across iOS, iPadOS, and macOS platforms. It introduces two primary models: the 3 billion parameter on-device model, referred to as AFM-on-device, and the more extensive server-based model known as AFM-server. Both models are built as dense, decoder-only Transformer architectures, optimized for efficiency while being tailored to execute a wide array of tasks with high accuracy and responsibility.
The training regimen for these models is extensive and multifaceted. It begins with core pre-training on a rich and diverse dataset comprising 6.3 trillion tokens, which lays a robust foundation for language understanding. Following this, the models undergo continued pre-training, where they process an additional 1 trillion tokens at longer sequence lengths. This phase is complemented by context lengthening, which incorporates 100 billion tokens at a 32k sequence length, further enhancing their ability to handle complex input.
Once the initial training phases are complete, a series of post-training techniques are applied. This includes supervised fine-tuning and reinforcement learning from human feedback (RLHF), utilizing innovative methodologies such as the iterative teaching committee (iTeC) and mirror descent with leave-one-out estimation (MDLOO). These techniques ensure that the models not only learn from vast amounts of data but also refine their responses based on real-world human interactions.
To enhance the models’ adaptability and efficiency, they are further specialized using LoRA (Low-Rank Adaptation) adapters. Additionally, optimization strategies such as quantization and pruning are employed to ensure these models operate efficiently on-device, making them suitable for mobile and edge environments.
Benchmarking results reveal that the AFM-on-device model significantly outperforms larger open-source alternatives like Mistral-7B, particularly in instruction-following and mathematical tasks. Meanwhile, the AFM-server model demonstrates competitive capabilities against GPT-3.5, showcasing its strength in general-purpose tasks. Notably, both models excel in safety evaluations, reflecting Apple’s unwavering commitment to the responsible deployment of artificial intelligence technologies.
This document underscores the sophisticated methodologies and optimizations involved in developing these high-performance, efficient, and responsible AI models, positioning Apple at the forefront of AI innovation.
Introduction
In an era where artificial intelligence is rapidly evolving, Apple is at the forefront of innovation with the introduction of its foundation language models, designed to power the next generation of Apple Intelligence across iOS, iPadOS, and macOS. These models—AFM-on-device, a streamlined 3 billion parameter model, and AFM-server, a more powerful server-based counterpart—embody Apple’s commitment to creating efficient, responsible, and privacy-focused AI solutions.
This paper delves into the sophisticated methodologies behind these models, which have been meticulously crafted to deliver exceptional performance across a wide array of tasks. With a robust training framework that incorporates over 6.3 trillion tokens, extended context capabilities, and advanced post-training techniques, Apple’s language models are not only built for accuracy but also designed with safety and ethical considerations at their core. As we explore the intricate training processes, optimization strategies, and performance benchmarks, it becomes clear that these models represent a significant leap forward in AI technology, poised to enhance user experiences while upholding Apple’s values of privacy and responsibility.
Apple has introduced its foundation language models that power Apple Intelligence features across iOS, iPadOS, and macOS. These models include a 3 billion parameter on-device model and a larger server-based model. Designed to perform a wide range of tasks efficiently, accurately, and responsibly, these models showcase Apple’s commitment to advanced AI while ensuring user privacy and device efficiency.
Method Overview
Models: AFM-on-device and AFM-server
Apple’s foundation models consist of two main types:
- AFM-on-device: A ~3 billion parameter model optimized for on-device performance.
- AFM-server: A larger, more powerful model designed for server-based tasks.
Both models are dense, decoder-only Transformer models featuring several architectural optimizations for enhanced efficiency.
Training Process
The training process for these models involves three main stages:
-
Core Pre-training:
- Dataset: A diverse, high-quality dataset comprising 6.3 trillion tokens from web pages, licensed datasets, code, math content, and public datasets. This data is meticulously filtered and processed.
- Objective: Develop a robust foundational understanding.
-
Continued Pre-training:
- Duration: 1 trillion tokens at longer sequence lengths.
- Data Mixture: Adjusted to enhance model capabilities over extended contexts.
-
Context Lengthening:
- Scope: 100 billion tokens at a 32k sequence length.
- Purpose: Improve the model’s ability to handle long-context tasks effectively.
Post-training Enhancements
For post-training, Apple employs advanced techniques:
- Supervised Fine-tuning: Tailors the model to align with specific tasks.
- Reinforcement Learning from Human Feedback (RLHF): Incorporates human feedback to refine model outputs.
Novel Techniques
- Iterative Teaching Committee (iTeC): A technique to iteratively improve model capabilities through expert committee reviews.
- Mirror Descent with Leave-One-Out Estimation (MDLOO): An advanced optimization technique to fine-tune model parameters efficiently.
Specialization and Optimization
The models are further specialized for specific tasks using LoRA (Low-Rank Adaptation) adapters, which can be dynamically loaded. To ensure efficiency, especially for on-device models, extensive optimizations like quantization and pruning are applied.
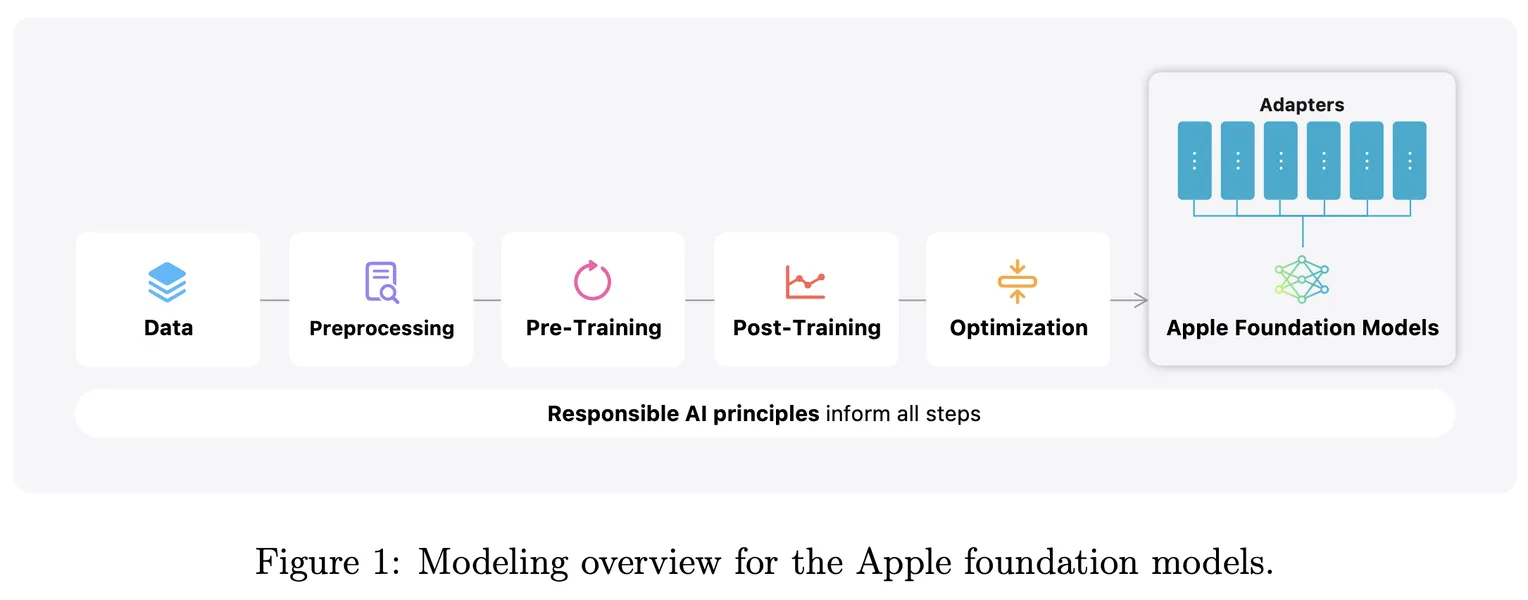
5 Powering Apple Intelligence Features
The foundation models developed for Apple Intelligence are meticulously crafted to enhance the user experience across iPhone, iPad, and Mac. Apple Intelligence serves as a personal intelligence system that leverages advanced language models to provide intelligent, context-aware functionalities. Central to this system is the understanding that the performance of these models is not just a matter of broad capabilities but hinges on their effectiveness in performing specific tasks relevant to users.
To achieve exceptional task performance, Apple has implemented a versatile architecture that utilizes runtime-swappable adapters. This architecture allows a single foundation model to dynamically specialize for a diverse range of tasks, effectively transforming its functionality on-the-fly. This capability enables even smaller models to reach best-in-class performance levels through targeted fine-tuning.
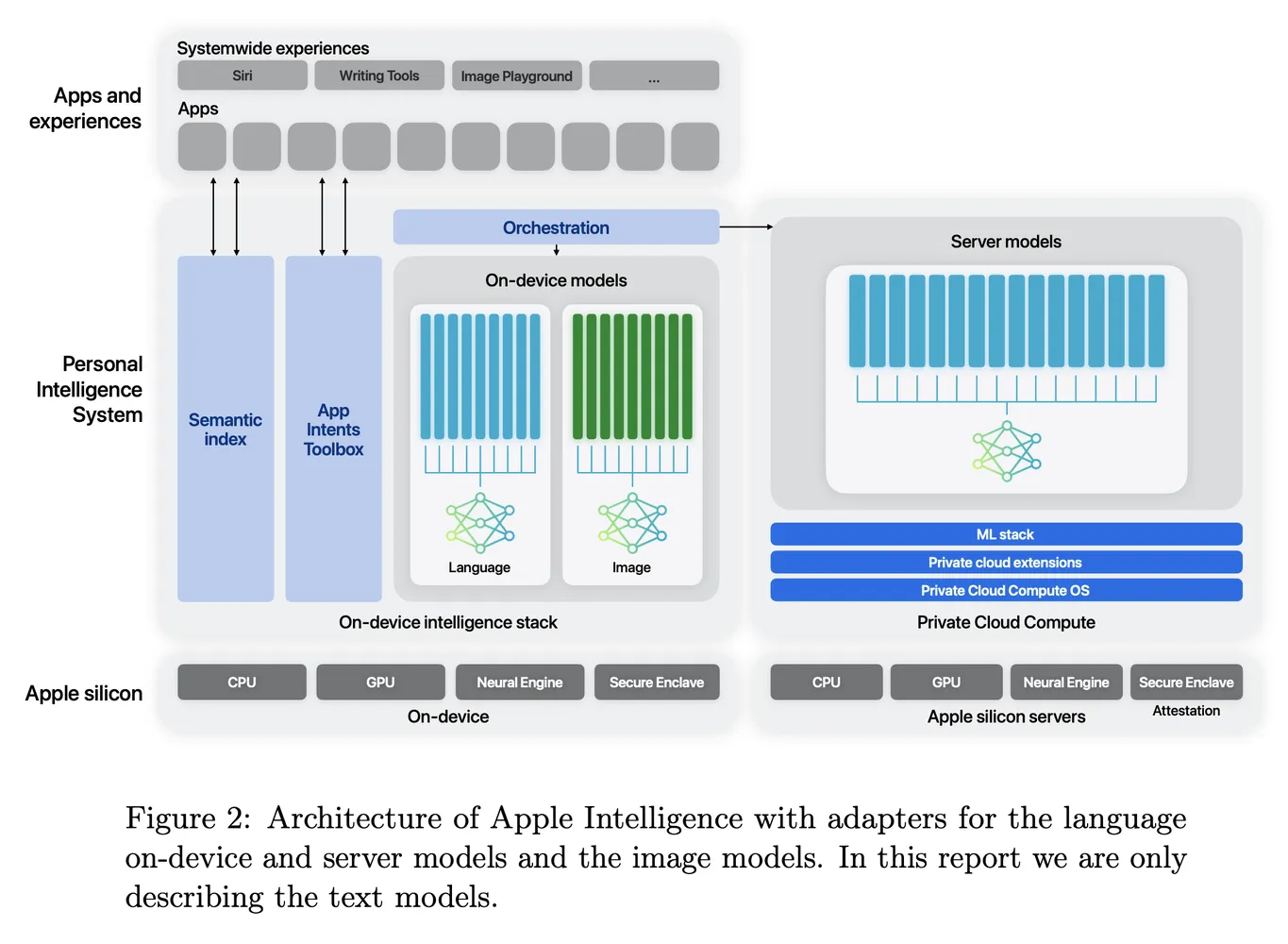
5.1 Adapter Architecture
The architecture of Apple Intelligence is driven by the use of LoRA (Low-Rank Adaptation) adapters—small neural network modules integrated into various layers of the base model. This design allows for task-specific fine-tuning without altering the original parameters of the pre-trained model. By focusing on the linear projection matrices within self-attention and fully connected layers, Apple maintains the foundational knowledge of the model while customizing it to enhance performance for specific applications.
For instance, the adapter parameters are represented using 16 bits, and for the ~3 billion parameter on-device model, these parameters typically occupy tens of megabytes. This efficient design allows adapters to be loaded dynamically, cached in memory, and swapped as needed. Consequently, Apple Intelligence can quickly adapt to different tasks while managing memory effectively and ensuring system responsiveness.
Moreover, Apple has developed a robust infrastructure to facilitate the rapid addition, retraining, testing, and deployment of these adapters. This infrastructure is essential for keeping pace with updates to the base model or training data, allowing for seamless enhancements and the introduction of new capabilities.
5.2 Optimizations
Optimizing both inference latency and power efficiency is crucial for delivering a seamless user experience. Apple employs several advanced optimization techniques to ensure that the foundation models operate efficiently on-device and within Private Cloud Compute environments.
Model Quantization Techniques
To fit the AFM models within the constrained memory budgets of edge devices and minimize inference costs, Apple utilizes model quantization. This technique reduces the effective bits per weight, allowing for a significant decrease in memory usage without substantially compromising model quality. Research has indicated that models quantized to 4 bits can maintain performance levels comparable to their 32/16-bit counterparts.
Apple’s state-of-the-art quantization methods, combined with accuracy-recovery adapters, enable near-lossless quantization with an average of less than 4 bits per weight. This approach ensures that the quantized models retain critical capabilities necessary for various product features. The accuracy-recovery adapters are trained to recover any quality lost during quantization, allowing application teams to fine-tune their feature-specific adapters efficiently.
Mixed-Precision Quantization
The architecture incorporates residual connections across transformer blocks, highlighting that not all layers carry equal importance. As a result, some layers can operate with 2-bit quantization instead of the default 4-bit. This mixed-precision approach enables the AFM-on-device model to achieve an average compression of around 3.5 bits per weight while maintaining significant model quality.
Interactive Model Analysis
To further refine the architecture, Apple employs Talaria, an interactive model latency and power analysis tool. This tool aids in selecting optimal bit rates for different operations, ensuring that the performance of the model aligns with the desired user experience.
5.3 Case Study: Summarization
A practical application of the AFM-on-device model is its role in powering summarization features for emails, messages, and notifications. While the base model demonstrates good general summarization capabilities, specific specifications and constraints often necessitate fine-tuning.
To enhance the model’s summarization ability, Apple fine-tunes a LoRA adapter atop the quantized AFM-on-device. This adapter is initialized from the accuracy-recovery adapter, ensuring that it leverages previously learned knowledge while specializing in summarization tasks.
The training data mixture includes synthetic summaries generated by the AFM-server, along with public datasets and vendor data, all of which are carefully filtered to ensure quality and compliance with user privacy standards. Rule-based and model-based filters refine the data further, ensuring that the fine-tuning process produces high-quality summaries that meet the product’s specifications.
Conclusion
The architecture of Apple Intelligence represents a significant advancement in AI, emphasizing efficiency, adaptability, and user-centric design. By integrating runtime-swappable adapters and employing sophisticated quantization and optimization techniques, Apple has created a foundation model that is not only powerful but also responsive to the diverse needs of its users. The commitment to maintaining high standards of quality and efficiency underscores Apple’s dedication to enhancing the user experience across its ecosystem of devices.
Results
Performance Benchmarks
The models demonstrate strong performance across various benchmarks:
- AFM-on-device: Outperforms larger open-source models like Mistral-7B in instruction following and math tasks.
- AFM-server: Achieves competitive performance against GPT-3.5 in general capabilities.
Safety and Responsibility
Both models exhibit superior performance in safety evaluations compared to open-source and commercial models, highlighting Apple’s commitment to responsible AI.
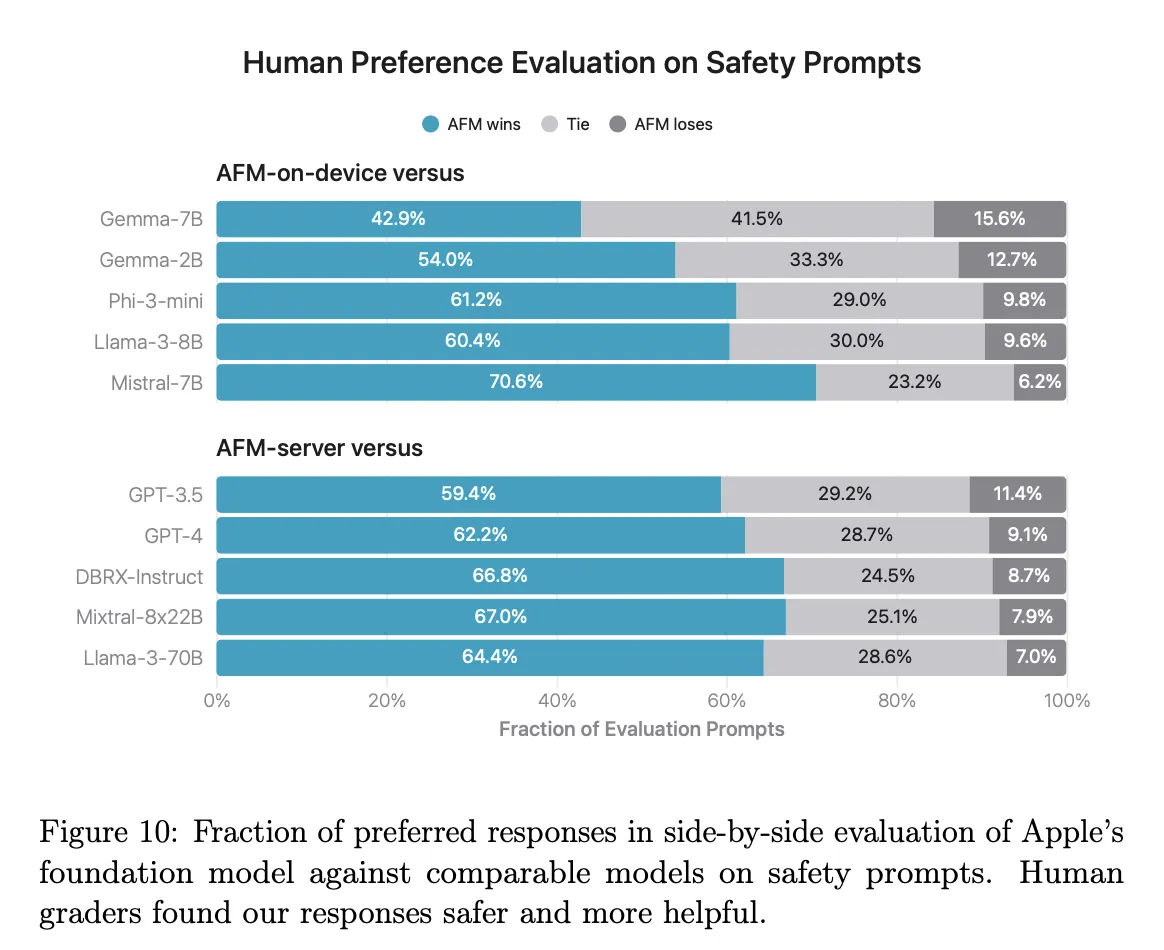
Conclusion
Apple’s foundation language models represent a significant advancement in AI capabilities, designed to power intelligent features across Apple devices. These models are not only fast and efficient but also aligned with Apple’s values of privacy and user-centric design.
For more detailed information, please refer to the full paper: Apple. “Apple Intelligence Foundation Language Models.” arXiv, 29 Jul. 2024, arxiv.org/abs/2407.21075.
Expanded Details
Introduction
At the 2024 Worldwide Developers Conference, Apple introduced Apple Intelligence, a personal intelligence system integrated deeply into iOS 18, iPadOS 18, and macOS Sequoia. Apple Intelligence consists of multiple highly capable generative models that are fast, efficient, specialized for users’ everyday tasks, and can adapt dynamically based on current activities.
Core Pre-training
Core pre-training forms the foundation of Apple’s language models. The data used spans various domains to ensure comprehensive learning:
- Web Pages: A significant portion of the dataset, providing diverse linguistic structures and contexts.
- Licensed Datasets: High-quality data curated and licensed specifically for training.
- Code and Math Content: Enhances the model’s ability to understand and generate code, as well as solve complex mathematical problems.
- Public Datasets: Includes freely available datasets that are carefully filtered to maintain quality.
This diverse dataset ensures that the model develops a robust understanding capable of generalizing across different tasks.
Continued Pre-training
To further enhance the model’s capabilities, continued pre-training is conducted with an adjusted data mixture:
- Longer Sequence Lengths: Training on longer sequences allows the model to better understand and generate extended contexts.
- Data Mixture Adjustment: Fine-tuning the mixture of data sources improves the model’s adaptability to various tasks.
Context Lengthening
Context lengthening is a crucial step in improving the model’s performance on tasks that require understanding and generating long sequences. By training on sequences up to 32k tokens, the model becomes adept at handling extended dialogues, long documents, and other tasks requiring extensive context.
Supervised Fine-tuning
Supervised fine-tuning tailors the model to specific tasks by providing labeled data. This process ensures that the model not only understands general language patterns but also excels in particular applications such as text generation, summarization, and more.
Reinforcement Learning from Human Feedback (RLHF)
RLHF involves incorporating human feedback into the training process to refine the model’s outputs. This iterative process helps the model align more closely with human preferences and expectations, enhancing its usability and reliability.
Iterative Teaching Committee (iTeC)
The iTeC technique involves a committee of experts who iteratively review and improve the model’s outputs. This approach ensures that the model benefits from diverse perspectives and expertise, leading to more refined and accurate performance.
Mirror Descent with Leave-One-Out Estimation (MDLOO)
MDLOO is an advanced optimization technique used to fine-tune the model parameters efficiently. By iteratively adjusting the parameters based on leave-one-out estimation, this technique helps achieve optimal performance with minimal computational overhead.
Specialization Using LoRA Adapters
LoRA adapters allow the models to be specialized for specific tasks dynamically. These adapters can be loaded as needed, providing flexibility and efficiency. This approach ensures that the models can handle a wide range of tasks without requiring extensive retraining for each new application.
Optimizations for Efficiency
To make the models efficient for on-device use, several optimizations are applied:
- Quantization: Reduces the model size and computational requirements without significantly impacting performance.
- Pruning: Removes redundant parameters, further enhancing efficiency.
These optimizations ensure that the models can run smoothly on devices with limited computational resources, providing fast and responsive performance.
Performance Benchmarks
The models have been evaluated across various benchmarks to assess their performance:
- Instruction Following: AFM-on-device demonstrates superior performance in following instructions compared to larger open-source models.
- Math Tasks: The model excels in solving mathematical problems, showcasing its advanced reasoning capabilities.
- General Capabilities: AFM-server performs competitively against GPT-3.5, highlighting its versatility and strength in general language tasks.
Safety and Responsibility
Safety evaluations indicate that Apple’s models outperform both open-source and commercial models in adhering to safety guidelines. This focus on responsible AI ensures that the models provide reliable and ethical outputs, aligning with Apple’s values.
Conclusion
Apple’s foundation language models represent a significant leap forward in AI capabilities. These models are designed to be fast, efficient, and highly capable, powering a wide range of intelligent features across Apple devices. By focusing on efficiency, accuracy, and responsibility, Apple sets a new standard for AI in consumer technology.
For comprehensive details, refer to the full paper: Apple. “Apple Intelligence Foundation Language Models.” arXiv, 29 Jul. 2024, arxiv.org/abs/2407.21075.
Free Custom ChatGPT Bot with BotGPT
To harness the full potential of LLMs for your specific needs, consider creating a custom chatbot tailored to your data and requirements. Explore BotGPT to discover how you can leverage advanced AI technology to build personalized solutions and enhance your business or personal projects. By embracing the capabilities of BotGPT, you can stay ahead in the evolving landscape of AI and unlock new opportunities for innovation and interaction.
Discover the power of our versatile virtual assistant powered by cutting-edge GPT technology, tailored to meet your specific needs.
Features
-
Enhance Your Productivity: Transform your workflow with BotGPT’s efficiency. Get Started
-
Seamless Integration: Effortlessly integrate BotGPT into your applications. Learn More
-
Optimize Content Creation: Boost your content creation and editing with BotGPT. Try It Now
-
24/7 Virtual Assistance: Access BotGPT anytime, anywhere for instant support. Explore Here
-
Customizable Solutions: Tailor BotGPT to fit your business requirements perfectly. Customize Now
-
AI-driven Insights: Uncover valuable insights with BotGPT’s advanced AI capabilities. Discover More
-
Unlock Premium Features: Upgrade to BotGPT for exclusive features. Upgrade Today
About BotGPT Bot
BotGPT is a powerful chatbot driven by advanced GPT technology, designed for seamless integration across platforms. Enhance your productivity and creativity with BotGPT’s intelligent virtual assistance.