
Understanding Low-Rank Adaptation (LoRA): Revolutionizing Fine-Tuning for Large Language Models
Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT FreeThis document explores the innovative approach of Low-Rank Adaptation (LoRA), a technique designed to enhance the efficiency and effectiveness of large language models (LLMs). As AI technology continues to advance, the need for adaptable and resource-efficient solutions has become paramount, particularly in the context of fine-tuning massive models like GPT-3 and beyond. LoRA addresses the challenges associated with traditional fine-tuning methods, which often demand extensive computational resources and time.
LoRA introduces a novel framework that leverages low-rank matrices, allowing for efficient adaptation of large models without the need for full retraining. By focusing on a smaller subset of parameters, LoRA significantly reduces the computational burden, making it feasible to tailor models for specific tasks or domains. This not only accelerates the training process but also enhances the overall performance of the models in real-world applications.
Throughout this document, we will delve into the intricacies of LoRA, examining how it operates and the advantages it brings to the machine learning landscape. By providing a comprehensive overview of LoRA’s methodologies and practical applications, this document aims to equip researchers, developers, and AI enthusiasts with the knowledge necessary to implement this transformative technique in their projects. As we navigate the future of AI, understanding LoRA will be essential for harnessing the full potential of large language models.
Introduction
The field of artificial intelligence (AI) has made remarkable strides in recent years, with large language models (LLMs) like GPT-4, LLaMa, and Claude 2 showcasing unprecedented capabilities in natural language understanding, text generation, and various other applications. However, these models come with their own set of challenges, primarily due to their immense size and complexity. Fine-tuning such models to adapt to specific tasks or domains requires significant computational resources and time, making it impractical for many use cases.
This is where Low-Rank Adaptation (LoRA) steps in. LoRA offers an innovative solution to the problem of fine-tuning large models by reducing the computational burden and making the adaptation process more efficient. This article will provide a comprehensive guide to understanding what LoRA is, how it works, and why it is revolutionizing the field of machine learning.
Learning Objectives
By the end of this article, you will be able to:
- Define “Low-Rank Adaptation” (LoRA)
- Explain how LoRA works in simple terms
- Understand the advantages of using LoRA in machine learning models
- Apply LoRA in practical scenarios using Python libraries
What is Low-Rank Adaptation (LoRA)?
Low-Rank Adaptation (LoRA) is a technique designed to efficiently adapt large machine learning models to new tasks or domains without the need for full retraining. Unlike traditional fine-tuning methods that require updating all the parameters of a model, LoRA introduces lightweight, changeable components known as low-rank matrices to the model. These matrices are significantly smaller and require fewer computational resources, making the adaptation process faster and more cost-effective.
Why Do We Need LoRA?
As machine learning models have grown in size, with some models like GPT-3 containing up to 175 billion parameters, the process of fine-tuning has become increasingly resource-intensive. Full fine-tuning, which involves retraining all the parameters of a model, can be prohibitively expensive and time-consuming. This is particularly true for specialized applications, such as adapting a model to work in specific domains like healthcare or finance.
LoRA addresses these challenges by allowing for the efficient fine-tuning of large models. By focusing on a smaller subset of parameters, LoRA significantly reduces the computational resources required, making it feasible to adapt large models for specific tasks without the need for extensive retraining.
How Does LoRA Work?
The Concept of Lower-Rank Matrices
To understand how LoRA works, it’s essential first to grasp the concept of lower-rank matrices. In linear algebra, a matrix is a rectangular array of numbers arranged in rows and columns. The rank of a matrix refers to the number of linearly independent rows or columns it contains, which is a measure of the “information content” or dimensionality of the data represented by the matrix.
A matrix is said to be of lower rank if its rank is less than the maximum possible rank given its size. For example, in a 3x3 matrix, if the rank is less than 3, it is considered a lower-rank matrix. Lower-rank matrices are particularly useful in data compression, where they help reduce the amount of data while preserving as much information as possible.
Applying Lower-Rank Matrices in LoRA
LoRA leverages the concept of lower-rank matrices to make the model training process more efficient. Instead of adjusting all the parameters of a large model during fine-tuning, LoRA decomposes the large weight matrices into smaller, lower-rank matrices. These smaller matrices contain fewer parameters, which drastically reduces the number of trainable parameters.
For example, in a model like GPT-3, which has 175 billion parameters, applying LoRA can reduce the number of trainable parameters by up to 10,000 times, bringing it down to around 17.5 million parameters. This reduction in the number of trainable parameters not only speeds up the training process but also decreases the computational resources required, making it financially viable to fine-tune large models.
Understanding LoRA with Matrices
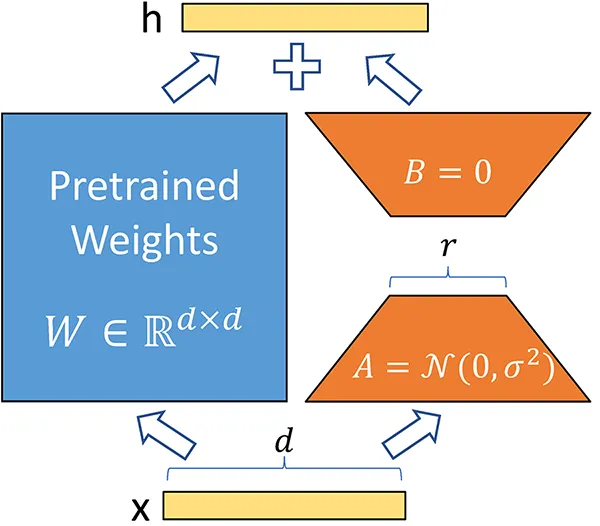
Original Weight Matrix
Let’s consider a large weight matrix
Where
Decomposing the Weight Matrix
In LoRA, we decompose the original weight matrix
Where:
is a low-rank matrix of size (where is the rank, typically much smaller than ). is a low-rank matrix of size .
The matrices can be represented as follows:
Matrix A (Low-Rank Component):
Matrix B (Low-Rank Component):
Combined Representation
The combined representation of the original weight matrix using LoRA becomes:
Training with LoRA
During the fine-tuning process, only the parameters of the low-rank matrices ( A ) and ( B ) are updated, while the original weight matrix ( W ) remains frozen. This approach effectively isolates the training to a smaller subset of parameters, significantly reducing the computational burden. By focusing on the low-rank matrices, we minimize the number of trainable parameters, which leads to a more efficient training process in terms of both time and resource utilization.
The rationale behind this technique is that the majority of the model’s learned features can be effectively captured by these low-rank adaptations. As a result, we can achieve a comparable performance to traditional fine-tuning methods, but with significantly fewer parameters to optimize. This is particularly advantageous in scenarios where computational resources are limited or where rapid iteration is necessary.
The update step can be summarized as:
In this equation,
By employing this technique, we ensure that the core structure of the model remains intact while still allowing it to adapt to new information. This approach not only enhances the efficiency of the training process but also promotes a more scalable model deployment, especially in applications where updates need to be made frequently or on-the-fly.
Furthermore, this method can lead to improved generalization. Since the original parameters remain unchanged, the model can retain its learned capabilities while gaining additional skills through the low-rank adaptations. This balance between stability and adaptability is crucial in building robust AI systems that can handle diverse tasks.
In summary, the use of LoRA in training allows for a more resource-efficient and scalable approach to model fine-tuning, making it an appealing choice for practitioners looking to enhance their AI systems without the overhead associated with traditional methods.
Advantages of Using LoRA
- Reduced Computational Cost: Training only the low-rank matrices decreases the overall number of trainable parameters.
- Maintained Performance: Despite fewer parameters, the performance of the model can remain high due to the effectiveness of low-rank approximations.
- Storage Efficiency: The size of checkpoints can be significantly reduced, as the low-rank matrices require less storage.
Summary
In conclusion, Low-Rank Adaptation leverages the decomposition of weight matrices into smaller, more manageable components, enabling efficient fine-tuning of large models without incurring the full cost of retraining. By understanding the matrix representations and operations involved, practitioners can effectively implement LoRA in their machine learning projects.
The LoRA Process in Detail
The LoRA process can be broken down into the following steps:
- Freezing the Original Model: The original pre-trained model is kept unchanged, meaning none of its parameters are altered during the adaptation process.
- Introducing Low-Rank Matrices: Low-rank matrices are introduced as additional components to the model. These matrices are small and contain fewer parameters, which makes them easier to train.
- Training the Low-Rank Matrices: During fine-tuning, only the parameters of the low-rank matrices are updated. This significantly reduces the computational burden and speeds up the training process.
- Inference: At inference time, the weights from the low-rank matrices are added to the original model’s weights, allowing the model to produce outputs that are tailored to the specific task or domain.
Example: Fine-Tuning GPT-3 with LoRA
To illustrate how LoRA works in practice, consider the task of fine-tuning GPT-3 for a specific domain, such as healthcare. In a traditional fine-tuning approach, all 175 billion parameters of GPT-3 would need to be retrained, which would require substantial computational resources and time.
Using LoRA, we can instead introduce low-rank matrices to the model. These matrices might contain only a few million parameters, which are then trained on a smaller healthcare-specific dataset. The original GPT-3 model remains unchanged, and only the low-rank matrices are updated. Once the training is complete, the low-rank matrices are combined with the original model’s parameters, allowing GPT-3 to generate text that is tailored to the healthcare domain.
Advantages of LoRA
LoRA offers several key advantages that make it an attractive option for fine-tuning large language models and other machine learning models.
-
Efficiency in Training and Deployment
LoRA significantly reduces the number of trainable parameters, which in turn reduces the computational resources required for training. This makes it possible to fine-tune large models on less powerful hardware, making the process more accessible and cost-effective. -
Maintaining Model Quality and Speed
Despite the reduction in the number of trainable parameters, LoRA maintains the quality and performance of the original model. The use of low-rank matrices ensures that the adapted model can still produce high-quality outputs without compromising on speed. -
Reduction in Checkpoint Sizes
One of the practical benefits of LoRA is the reduction in checkpoint sizes. For instance, in the case of GPT-3, the checkpoint size was reduced from 1 TB to just 25 MB when using LoRA. This reduction in storage requirements makes it easier to manage and deploy models in production environments. -
No Additional Inference Latency
LoRA does not introduce any additional latency during inference. The low-rank matrices are merged with the original model’s parameters for inference, ensuring that the model’s speed remains unchanged. This allows for rapid model switching at runtime without any additional overhead. -
Versatility
LoRA is a versatile technique that can be applied to any model that utilizes matrix multiplication. This includes not only large language models but also other types of machine learning models, such as support vector machines. LoRA’s broad applicability makes it a valuable tool for a wide range of applications.
LoRA in Image Models: Stable Diffusion
While LoRA is primarily discussed in the context of language models, it is also widely adopted in image models like Stable Diffusion. The principles behind LoRA remain the same, but the application differs slightly.
Adapting Image Models with LoRA
In image models like Stable Diffusion, the primary goal of fine-tuning is often style specialization or character specialization. For example, a model might be fine-tuned to generate images in a specific artistic style, such as anime or oil painting, or to consistently generate images of a particular character.
Using LoRA, only the lower-rank matrices are trained on small datasets that reflect the desired style or character. These matrices are then added to the original model, allowing it to generate images that match the specific requirements.
Use Cases in Stable Diffusion
Some common uses of LoRA in Stable Diffusion models include:
- Style Specialization: Adapting the model to generate images in specific styles, such as anime or oil painting.
- Character Specialization: Fine-tuning the model to consistently generate images of specific characters, such as Mario or SpongeBob.
- Quality Improvements: Enhancing the quality of generated images, such as improving facial details or adding more intricate textures.
Users can combine multiple LoRAs to achieve outputs that reflect multiple specializations simultaneously.
Combining LoRA with Prefix-Tuning
Another powerful technique that can be combined with LoRA is prefix-tuning. Prefix-tuning involves adding a prefix to the input sequence that the model processes, effectively guiding the model’s output toward a specific style or domain.
How Prefix-Tuning Works
In prefix-tuning, a small number of tokens are added to the beginning of the input sequence. These tokens are learned during the fine-tuning process and act as a guide for the model, influencing its output. When combined with LoRA, prefix-tuning allows for even more precise control over the model’s behavior.
Example: Combining LoRA and Prefix-Tuning
Consider a scenario where you want to fine-tune GPT-3 to generate legal documents. By using LoRA, you can reduce the number of trainable parameters and focus the training process on a smaller, legal-specific dataset. Then, by applying prefix-tuning, you can add a few tokens to the beginning of each input sequence that guide the model toward generating text in a formal, legalistic style.
This combination of techniques allows for highly efficient and effective fine-tuning, enabling the model to generate outputs that are closely aligned with the desired domain or style.
Practical Applications and Examples
LoRA is a versatile technique that can be applied to a wide range of tasks and domains. Some practical applications include:
- Custom Language Models: Fine-tuning large language models like GPT-3 or GPT-4 for specific tasks, such as customer service, legal document generation, or creative writing.
- Image Generation: Adapting models like Stable Diffusion to generate images in specific styles or featuring specific characters.
- Speech Recognition: Fine-tuning speech recognition models to work in noisy environments or to recognize specific accents or dialects.
- Healthcare: Adapting models to work in the healthcare domain, where privacy and security are paramount, and computational resources may be limited.
Implementing LoRA in Python
The practical implementation of LoRA in Python is relatively straightforward, thanks to libraries like Hugging Face Transformers, which offer built-in support for LoRA.
Example: Fine-Tuning GPT-3 with LoRA
Here is a simple example of how to fine-tune GPT-3 using LoRA in Python:
from transformers import GPT2Tokenizer, GPT2LMHeadModel, Trainer, TrainingArguments
# Load the pre-trained GPT-3 model and tokenizermodel = GPT2LMHeadModel.from_pretrained("gpt-3")tokenizer = GPT2Tokenizer.from_pretrained("gpt-3")
# Define the training datasettrain_dataset = [ {"input_ids": tokenizer.encode("Example input text", return_tensors="pt"), "labels": tokenizer.encode("Example output text", return_tensors="pt")}]
# Set up LoRA by defining low-rank matriceslora_rank = 8 # Set the rank of the low-rank matriceslora_matrices = model.add_low_rank_matrices(rank=lora_rank)
# Define the training argumentstraining_args = TrainingArguments( output_dir="./results", num_train_epochs=3, per_device_train_batch_size=2, save_steps=10_000, save_total_limit=2, logging_dir="./logs",)
# Create the Trainer objecttrainer = Trainer( model=model, args=training_args, train_dataset=train_dataset,)
# Train the modeltrainer.train()
# Save the fine-tuned modelmodel.save_pretrained("./fine-tuned-gpt-3")This example demonstrates how to set up LoRA for fine-tuning GPT-3, reduce the number of trainable parameters by introducing low-rank matrices, and then train the model on a small dataset.
Conclusion
Low-Rank Adaptation (LoRA) is a groundbreaking technique that addresses the challenges of fine-tuning large models. By reducing the number of trainable parameters and leveraging the power of low-rank matrices, LoRA makes the adaptation process more efficient, cost-effective, and accessible. Whether you’re working with large language models like GPT-3 or image models like Stable Diffusion, LoRA offers a powerful solution for fine-tuning models to meet specific needs.
As AI continues to evolve, techniques like LoRA will play a crucial role in making advanced machine learning models more adaptable and versatile. By mastering LoRA, you’ll be well-equipped to take advantage of the latest advancements in the field and apply them to your own projects.
Summary
- LoRA: A technique for efficiently adapting large models by introducing low-rank matrices, reducing the number of trainable parameters.
- Advantages: Efficient training, reduced checkpoint sizes, no additional inference latency, versatile application across various models.
- Practical Use Cases: Language models, image generation, speech recognition, and more.
- Implementation: LoRA can be implemented in Python using libraries like Hugging Face Transformers, allowing for efficient fine-tuning of models like GPT-3.
By following the guidance provided in this article, you’ll be able to implement LoRA in your own projects and take advantage of its many benefits.
Free Custom ChatGPT Bot with BotGPT
To harness the full potential of LLMs for your specific needs, consider creating a custom chatbot tailored to your data and requirements. Explore BotGPT to discover how you can leverage advanced AI technology to build personalized solutions and enhance your business or personal projects. By embracing the capabilities of BotGPT, you can stay ahead in the evolving landscape of AI and unlock new opportunities for innovation and interaction.
Discover the power of our versatile virtual assistant powered by cutting-edge GPT technology, tailored to meet your specific needs.
Features
-
Enhance Your Productivity: Transform your workflow with BotGPT’s efficiency. Get Started
-
Seamless Integration: Effortlessly integrate BotGPT into your applications. Learn More
-
Optimize Content Creation: Boost your content creation and editing with BotGPT. Try It Now
-
24/7 Virtual Assistance: Access BotGPT anytime, anywhere for instant support. Explore Here
-
Customizable Solutions: Tailor BotGPT to fit your business requirements perfectly. Customize Now
-
AI-driven Insights: Uncover valuable insights with BotGPT’s advanced AI capabilities. Discover More
-
Unlock Premium Features: Upgrade to BotGPT for exclusive features. Upgrade Today
About BotGPT Bot
BotGPT is a powerful chatbot driven by advanced GPT technology, designed for seamless integration across platforms. Enhance your productivity and creativity with BotGPT’s intelligent virtual assistance.