
Retrieval-Augmented Generation (RAG): Enhancing NLP Models
Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT Free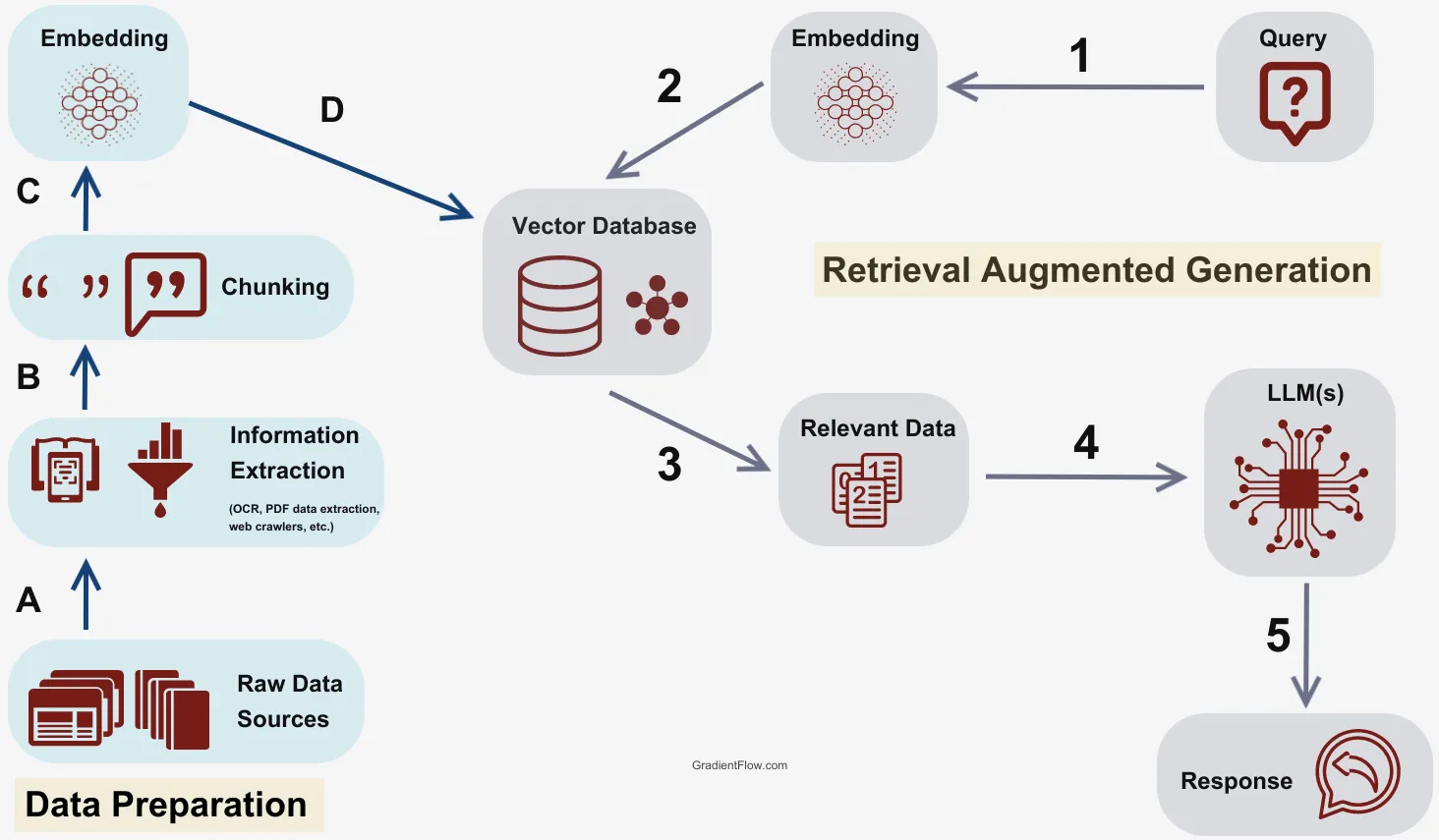
Retrieval-Augmented Generation (RAG) is a powerful technique combining retrieval mechanisms with generative models to enhance natural language processing (NLP) tasks, ensuring more accurate and reliable outputs. This approach leverages external knowledge sources, streamlining the creation of intelligent NLP models.
How RAG Works
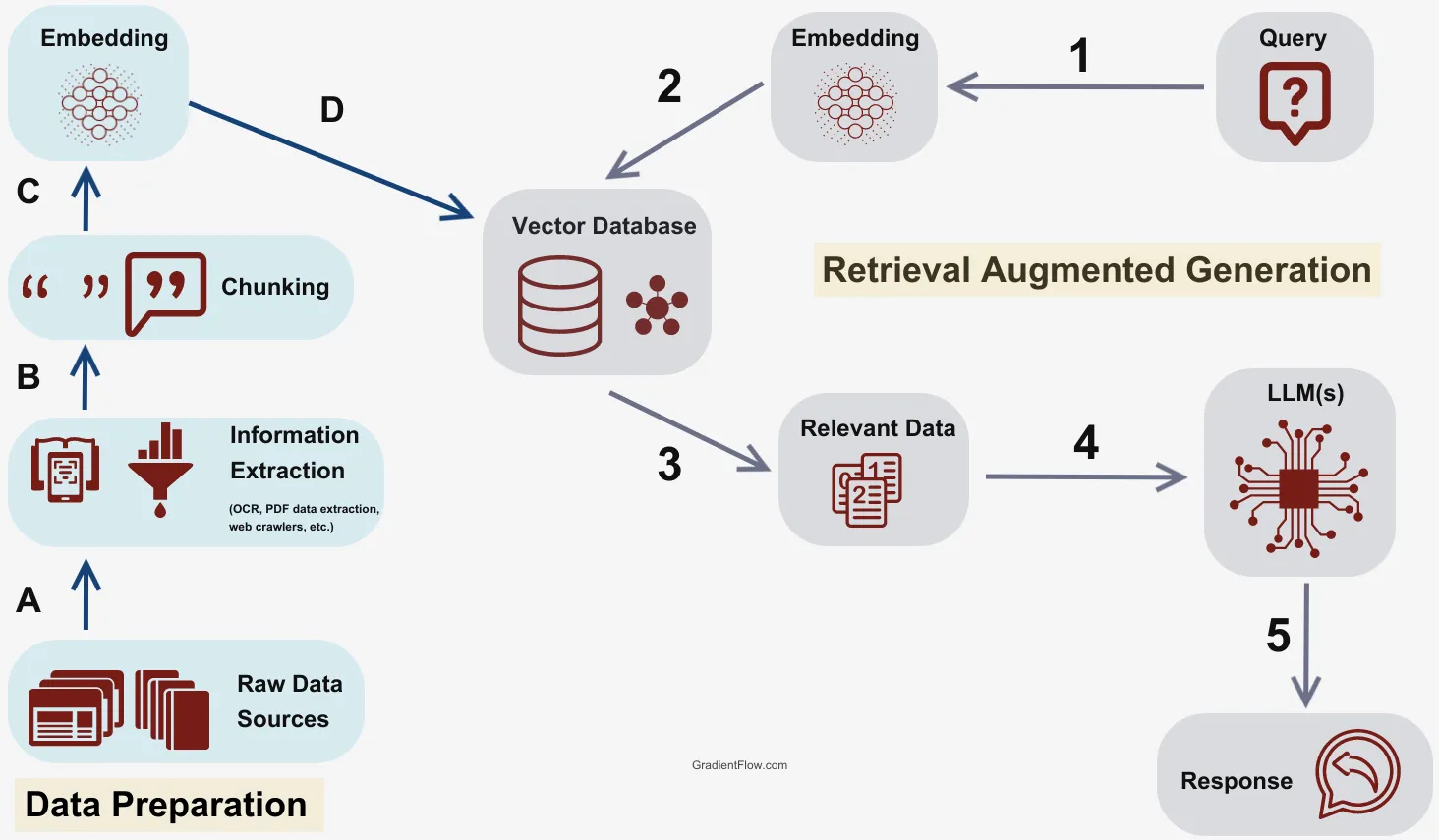
RAG integrates a retrieval component with a text generator model. It retrieves relevant documents from a knowledge base, such as Wikipedia, and uses these documents as context to generate the final response. This method improves the factual consistency of generated outputs, mitigating issues like hallucination and keeping information up-to-date without the need for retraining the entire model.
Key Advantages of RAG
- Factual Consistency: By accessing up-to-date information, RAG reduces the likelihood of generating outdated or incorrect information.
- Efficiency: RAG fine-tunes models more efficiently, avoiding the need for extensive retraining.
- Adaptability: The system can adapt to evolving information, making it ideal for dynamic fields where knowledge constantly changes.
Applications
RAG has demonstrated significant improvements in various benchmarks, including:
- Natural Questions: Enhances response quality and factuality.
- WebQuestions: Provides specific and diverse answers.
- MS-MARCO and Jeopardy: Generates more accurate responses.
Use Case: Generating Machine Learning Paper Titles
Generating concise and relevant machine learning paper titles is a significant yet practical application of RAG. This use case highlights RAG’s potential to streamline academic and research workflows, ensuring that the titles are not only accurate but also engaging and contextually appropriate. Here’s an in-depth look at how RAG can revolutionize this aspect of research.
Natural Language Processing (NLP) has been an integral part of AI research, with recent advancements shifting towards general-purpose language models. Among these advancements, Retrieval-Augmented Generation (RAG) stands out for its ability to generate contextually relevant text by combining retrieval systems and generative models. A compelling application of RAG in the academic realm is the generation of concise and relevant machine learning paper titles.
The Significance of Effective Paper Titles
A research paper’s title is crucial as it serves as the initial point of engagement for readers. It must be concise, informative, and appealing to accurately reflect the paper’s content and attract the intended audience. Crafting such titles manually can be laborious, requiring a balance between brevity and informativeness. RAG offers a solution to automate this process, ensuring high-quality titles efficiently.
How RAG Facilitates Title Generation
Input and Retrieval
- Initial Input: Researchers provide RAG with key themes, findings, and important concepts from their paper.
- Document Retrieval: RAG searches through a comprehensive database of existing literature, such as papers, articles, and academic resources, ensuring the generated titles are grounded in current research trends and terminology.
Contextual Analysis
- Concatenation: The retrieved documents are concatenated with the initial input, providing a rich context for the title generation process.
- Semantic Understanding: RAG’s seq2seq model comprehends the semantics of both the input and the retrieved documents, ensuring contextually relevant title generation.
Title Generation
- Title Proposal: Utilizing the combined input and context, RAG generates multiple potential titles.
- Filtering and Selection: Researchers review the proposed titles, selecting the most suitable one or refining the suggestions further.
Benefits of Using RAG for Title Generation
Time Efficiency
- Automated Process: RAG automates the title generation process, saving researchers significant time that would otherwise be spent brainstorming and refining titles.
- Rapid Iteration: Researchers can quickly generate and review multiple title options, accelerating the publication preparation process.
Consistency and Relevance
- Current Trends: By retrieving and analyzing recent literature, RAG ensures that the generated titles reflect current trends and terminologies in the field.
- Accuracy: The dual knowledge sources (parametric and nonparametric memory) help RAG produce accurate and contextually relevant titles, reducing the risk of misleading or vague titles.
Enhanced Discoverability
- Keyword Optimization: RAG can incorporate relevant keywords into the titles, enhancing the paper’s discoverability in academic databases and search engines.
- Engaging Titles: Well-crafted titles can attract more readers, increasing the paper’s reach and impact.
Real-World Examples
Academic Research
In academic settings, RAG can significantly streamline the workflow for researchers. For instance, when working on a paper about advancements in neural network optimization, researchers can input the main findings and key terms. RAG will then retrieve relevant documents and generate titles such as “Advancements in Neural Network Optimization: A Comprehensive Study” or “Innovative Approaches to Neural Network Efficiency.”
Machine Learning Conferences
For machine learning conferences, generating engaging and relevant paper titles is crucial for the submission process. RAG can assist in creating titles that not only capture the essence of the research but also appeal to the conference reviewers and attendees. For example, a paper on the application of machine learning in healthcare might result in titles like “Revolutionizing Healthcare: Machine Learning Applications in Medical Diagnosis” or “Enhancing Patient Care with Machine Learning: New Frontiers in Health Tech.”
Technical Implementation of RAG for Title Generation
Preprocessing
- Data Collection: Gather a dataset of existing machine learning paper titles and their corresponding abstracts or summaries.
- Tokenization: Tokenize the input data to convert text into a format suitable for the model.
Model Training
- Fine-Tuning: Fine-tune a pretrained seq2seq model (such as BART) on the collected dataset, enabling it to learn the patterns and structures of effective paper titles.
- Retrieval Component: Integrate a dense-passage retrieval system to fetch relevant documents based on the input data.
Generation and Evaluation
- Title Generation: Input the key themes and findings of the new paper into the fine-tuned RAG model to generate potential titles.
- Evaluation: Assess the generated titles for relevance, clarity, and engagement. Researchers can select the best title or use it as a basis for further refinement.
Future Directions and Challenges
Quality of Retrieved Documents
The quality of the retrieved documents is a critical factor in the success of RAG-generated titles. Ensuring that the retrieval component fetches relevant and high-quality documents is essential. Future research should focus on improving retrieval mechanisms to enhance the overall performance of RAG.
Integration with Other AI Techniques
Integrating RAG with other advanced AI techniques, such as reinforcement learning, could lead to more sophisticated models capable of complex decision-making tasks. This integration could further improve the quality and relevance of the generated titles, making RAG an even more valuable tool in academic and research settings.
Expanding the Scope of Applications
While the current focus is on generating machine learning paper titles, the potential applications of RAG extend beyond this. It could be used for generating titles and abstracts for various types of research papers, articles, and even books, making it a versatile tool for content creation across different domains.
Conclusion
Retrieval-Augmented Generation represents a significant advancement in natural language processing. By combining the strengths of retrieval systems and generative models, RAG provides a robust framework for generating accurate, reliable, and contextually appropriate text. Its application in generating machine learning paper titles showcases its potential to streamline academic workflows, enhance discoverability, and ensure relevance and engagement. As RAG continues to evolve, it promises to revolutionize various aspects of research and content creation, paving the way for more intelligent and efficient language processing systems.
The Challenge of Contextualization in NLP
Creating a model that can not only generate text but also research and contextualize information is a more complex challenge. However, this capability is crucial for future advancements in AI. One significant breakthrough in this area is the Retrieval-Augmented Generation (RAG) architecture. RAG is an end-to-end differentiable model combining an information retrieval component with a seq2seq (sequence-to-sequence) generator.
The Mechanics of RAG
RAG operates like a standard seq2seq model by taking in one sequence and outputting a corresponding sequence. However, it introduces an intermediary step that sets it apart from typical seq2seq methods. Instead of passing the input directly to the generator, RAG uses the input to retrieve a set of relevant documents from sources like Wikipedia. For example, given the prompt, “When did the first mammal appear on Earth?” RAG might retrieve documents related to “Mammal,” “History of Earth,” and “Evolution of Mammals.” These supporting documents are then concatenated with the original input and fed to the seq2seq model, which generates the final output.
Dual Knowledge Sources
RAG has two knowledge sources: the parametric memory (the knowledge stored in the seq2seq model’s parameters) and the nonparametric memory (the knowledge stored in the corpus from which RAG retrieves passages). These two sources complement each other. The nonparametric memory helps cue the seq2seq model to generate accurate responses, combining the flexibility of the closed-book (parametric-only) approach with the performance of open-book (retrieval-based) methods.
Late Fusion Technique
RAG uses a technique called late fusion to integrate knowledge from all retrieved documents. This means it makes individual answer predictions for each document-question pair and then aggregates the final prediction scores. Critically, late fusion allows back-propagation of error signals in the output to the retrieval mechanism, significantly improving the end-to-end system’s performance.
Applications of RAG
RAG’s architecture enables it to excel in various NLP applications, including:
-
Question Answering: RAG outperforms traditional models in benchmarks like Natural Questions and WebQuestions by providing more specific and accurate answers.
-
Information Retrieval: In customer support scenarios, RAG retrieves relevant information from a company’s knowledge base, generating helpful responses to customer queries.
-
Content Generation: RAG is useful for drafting articles, generating summaries, or creating educational materials, ensuring the content is both informative and accurate.
-
Research and Academia: In academic settings, RAG can generate concise and relevant titles for machine learning papers, draft abstracts, or provide literature reviews, streamlining research workflows and enhancing productivity.
Case Study: Generating Machine Learning Paper Titles
To demonstrate RAG’s practical application, consider the task of generating machine learning paper titles. Researchers can input the main themes and findings of their paper, and RAG can generate a list of potential titles grounded in relevant literature. This process saves time and ensures that the titles are contextually appropriate and engaging.
Future Directions and Challenges Despite its advantages, RAG faces challenges. The quality of retrieved documents is a primary concern. If the retrieval component fetches irrelevant or low-quality documents, the generative model’s output can suffer. Ongoing research aims to improve retrieval mechanisms to ensure high-quality information. Integrating RAG with other advanced AI techniques, such as reinforcement learning, could lead to more sophisticated models capable of complex decision-making tasks.
Conclusion Retrieval-Augmented Generation represents a significant advancement in natural language processing. By combining retrieval systems’ strengths and generative models, RAG provides a robust framework for generating accurate, reliable, and contextually appropriate text. Its applications are vast, ranging from question answering and information retrieval to content generation and academic research. As RAG evolves, it promises to pave the way for more intelligent and efficient language processing systems.
Conclusion
Retrieval-Augmented Generation is a promising advancement in NLP, combining the strengths of retrieval systems and generative models. It paves the way for more intelligent, reliable, and efficient language processing applications.