
Building Large Language Models for Multimodal Understanding and Generation
Enhance Your Writing with WordGPT Pro
Write Documents with AI-powered writing assistance. Get better results in less time.
Try WordGPT FreeBuild your custom chatbot with BotGPT
You can build your customer support chatbot in a matter of minutes.
Get StartedIntroduction
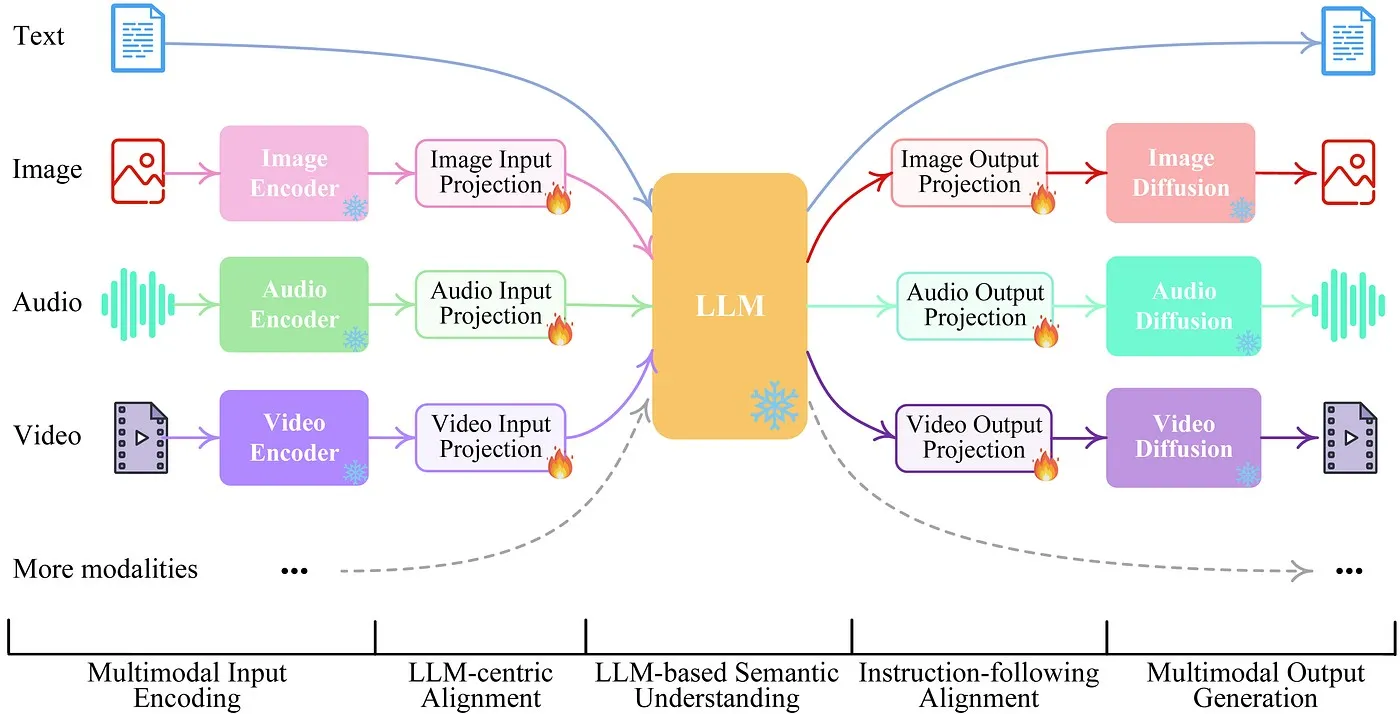
Large Language Models (LLMs) have revolutionized the field of natural language processing (NLP) by pushing the boundaries of what is achievable with text-based data. These models have demonstrated remarkable proficiency in tasks such as text generation, language translation, and sentiment analysis. However, human communication is inherently multimodal, extending beyond text to include images, sounds, and other sensory inputs. To capture this richness and complexity, there is a growing emphasis on developing multimodal LLMs that can process and generate content across various modalities.
Multimodal LLMs aim to integrate and synthesize information from diverse data sources, such as text, images, audio, and potentially even tactile inputs. This integration allows for more nuanced and human-like interactions with AI systems. In this article, we will explore the journey of building multimodal LLMs, delving into the associated challenges, methodologies, and potential applications.
The Need for Multimodal LLMs
Human communication is inherently multimodal, involving a combination of sensory inputs to convey and interpret information effectively. Traditional LLMs, which focus primarily on textual data, often fall short of capturing the full spectrum of human communication. Multimodal LLMs address this limitation by integrating information from multiple sources, thereby providing a more comprehensive understanding and generation of content.
2.1 Understanding Multimodality
Multimodal communication involves integrating various types of sensory inputs. Each modality contributes unique information that enhances our understanding of the content. Here is a closer look at the different modalities:
-
Text: The primary medium for written information. Text provides detailed and structured content that conveys complex ideas and instructions. It can represent factual information, narratives, and even emotional states through the choice of words and phrasing.
-
Images: Visual representations that offer context and additional details. Images can convey information that complements or enhances textual content, such as illustrations, charts, and photographs. They can also provide visual context that is not easily described in words.
-
Audio: Includes sounds and speech, adding layers of tone, emotion, and additional context. Audio elements like intonation, pitch, and rhythm can convey nuances that are often missing in text. Speech can include dialogues, monologues, and other vocal expressions that enrich the communication experience.
-
Tactile: Though less commonly integrated in current models, tactile feedback involves touch-based interactions. This modality is crucial for applications in virtual reality (VR) and augmented reality (AR), where users interact with digital objects in a tactile manner.
2.2 Advantages of Multimodal LLMs
The integration of multiple modalities offers several advantages:
-
Enhanced Contextual Understanding: Multimodal LLMs combine information from text, images, and audio to provide a richer context. For example, a model trained on both text and images can better understand the nuances of a visual description and generate more accurate and contextually relevant content.
-
Improved User Interaction: Multimodal systems enable more natural and intuitive interactions. For instance, voice assistants that use visual displays can provide more comprehensive responses, and systems that integrate audio and text can create more engaging and interactive experiences.
-
Versatile Applications: Multimodal LLMs can be applied to a wide range of fields, from content creation and education to accessibility technology. These models can generate multimedia content, develop interactive educational tools, and create assistive technologies that cater to diverse user needs.
Challenges in Multimodal Understanding and Generation
Developing multimodal LLMs involves several challenges, each of which requires careful consideration and innovative solutions.
3.1 Data Representation
Different modalities have distinct data formats, making it challenging to develop a unified representation:
-
Text: Represented as sequences of tokens or characters. Natural language processing (NLP) techniques are used to analyze and generate text. Text data is often processed into embeddings or vector representations that capture semantic meaning.
-
Images: Represented as pixel grids or feature maps. Computer vision techniques are used to analyze visual content. Images are processed into feature vectors or embeddings that capture visual patterns and objects.
-
Audio: Represented as waveforms or spectrograms. Audio processing techniques are employed to analyze and synthesize sound. Audio data is converted into features that represent temporal and spectral information.
To create a unified representation, models must align and standardize these diverse data types into a common feature space. This involves developing methods to integrate different modalities while preserving their unique characteristics.
3.2 Alignment and Fusion
Aligning and fusing information from different modalities is complex and involves several tasks:
-
Integrate Features: Combining features from text, images, and audio in a coherent manner. This requires methods to merge different types of data while maintaining their individual contributions. For example, integrating text descriptions with corresponding images involves aligning textual and visual features.
-
Understand Relationships: Grasping how modalities interact and influence each other. For instance, understanding how a textual description relates to visual content involves capturing the semantic relationship between text and images.
-
Generate Synchronized Outputs: Producing outputs that appropriately combine or transition between modalities. For example, generating a textual description of an image requires synchronizing visual and textual information to ensure coherence and relevance.
3.3 Scalability and Efficiency
Processing multimodal data is resource-intensive and presents several challenges:
-
Computational Load: Handling multiple types of data simultaneously requires significant processing power and memory. Multimodal models must be designed to efficiently manage and process large volumes of data from different sources.
-
Training Time: Training multimodal models involves extended periods due to the complexity of the data and the need for fine-tuning. Training times can be lengthy, requiring careful management of computational resources.
-
Cost: Significant costs are associated with computational resources and data storage. The infrastructure needed to support multimodal LLMs can be expensive, posing challenges for widespread adoption and deployment.
Methodologies for Multimodal LLM Development
Several methodologies are employed to develop multimodal LLMs, each addressing different aspects of the integration and processing of multimodal data.
4.1 Unified Representation Learning
Creating a unified representation involves techniques that enable the comparison and integration of different modalities:
-
Contrastive Learning: This technique involves finding a common feature space where different modalities can be compared. For instance, a model can be trained to minimize the distance between embeddings of semantically similar items across modalities while maximizing the distance between dissimilar items.
-
Embedding Techniques: Developing embeddings that capture the essence of each modality in a shared space. Embeddings are vector representations that encode the semantic information of different modalities, allowing for effective integration and comparison.
4.2 Cross-Modal Attention Mechanisms
Cross-modal attention mechanisms enable models to dynamically focus on relevant information from different modalities:
-
Focus on Relevant Information: Cross-modal attention allows models to attend to information from one modality based on the context provided by another. For example, understanding a text-based query about an image involves integrating information from both modalities to generate a coherent response.
-
Modify Self-Attention: Adapt the transformer’s self-attention mechanism to operate over concatenated embeddings from multiple modalities. This modification enables the model to learn cross-modal relationships and interactions, improving its ability to process and generate multimodal content.
4.3 Generative Pretraining for Multimodality
Pretraining models on multimodal data involves several key approaches:
-
Generative Objectives: Training models to predict or generate data across modalities. For example, using masked language modeling for text and a similar masking objective for images helps the model learn a broad understanding of multimodal content.
-
Fine-Tuning: Tailoring the pretrained model for specific tasks such as image captioning or text-to-image generation. Fine-tuning involves adapting the model to particular applications, improving its performance on specialized tasks.
4.4 Efficient Data Processing Pipelines
Developing efficient data processing pipelines involves optimizing how data is handled and processed:
-
Data Loaders: Specialized loaders that handle various data types and preprocess them into a uniform format suitable for model consumption. These loaders ensure that different modalities are prepared and formatted correctly for integration into the model.
-
Batching Strategies: Optimizing how data is batched and processed to improve efficiency and scalability. Efficient batching techniques help manage large and varied datasets, reducing training times and computational overhead.
Applications of Multimodal LLMs
Multimodal LLMs have a wide range of applications, each leveraging their ability to integrate and process multiple types of data.
5.1 Content Creation
Multimodal LLMs can enhance the content creation process by generating multimedia outputs:
-
Automated Media Generation: Creating articles with relevant images, videos, and other media. This capability streamlines content creation and improves the quality of multimedia outputs by ensuring that visual and textual elements are harmoniously integrated.
-
Interactive Storytelling: Generating stories that include multimedia elements such as illustrations, sound effects, and animations. This approach creates more engaging and immersive narrative experiences for users.
5.2 Education and Training
In educational contexts, multimodal LLMs offer several benefits:
-
Interactive Learning Materials: Combining text, diagrams, and audio explanations to create engaging educational content. This multimodal approach caters to diverse learning styles and improves comprehension by providing multiple forms of information.
-
Personalized Learning: Tailoring educational resources based on individual learning styles and preferences. Multimodal LLMs can adapt content to better suit the needs of different learners, enhancing the effectiveness of educational interventions.
5.3 Accessible Technology
Multimodal LLMs can significantly improve accessibility for users with diverse needs:
-
Content Translation: Converting text descriptions into images or audio for accessibility. This capability helps make information more accessible to individuals with visual or auditory impairments, enhancing their ability to interact with digital content.
-
Assistive Tools: Developing tools that aid users with disabilities, such as text-to-speech systems for visually impaired individuals. Multimodal LLMs can create more inclusive technologies that cater to a broader range of user needs.
Case Studies and Examples
Examining real-world implementations and research provides valuable insights into the practical applications of multimodal LLMs.
6.1 Industry Implementations
Several companies have successfully implemented multimodal LLMs:
-
Google’s DeepMind: DeepMind has developed multimodal models that integrate text, images, and audio to enhance AI capabilities. Their work includes advancements in generating descriptive captions for images and creating more sophisticated conversational agents.
-
Microsoft Azure: Microsoft Azure offers multimodal AI services that combine text, images, and audio for various enterprise applications. These services include tools for content generation, data analysis, and user interaction.
6.2 Research and Development
Academic research contributes to the advancement of multimodal LLMs:
-
Academic Contributions: Key research papers and findings in the field of multimodal AI provide insights into new methodologies, techniques, and theoretical advancements. Research from institutions such as Stanford University and MIT has explored novel approaches to integrating and processing multimodal data.
-
Innovative Approaches: New methodologies and technologies emerging from academic research include advancements in cross-modal attention, unified representation learning, and generative pretraining. These innovations drive progress in the field and inform the development of practical applications.
Future Directions and Trends
Looking ahead, several emerging technologies and trends will shape the future of multimodal LLMs:
7.1 Emerging Technologies
-
Neurosymbolic Integration: Combining neural and symbolic approaches for better multimodal understanding. Neurosymbolic AI aims to integrate deep learning with symbolic reasoning to enhance the ability of models to process and generate multimodal content.
-
Advancements in Hardware: Innovations in computing hardware, such as specialized processors and accelerators, will support the development of more efficient multimodal AI systems. These advancements will enable the handling of larger datasets and more complex models.
7.2 Ethical and Societal Implications
Addressing ethical and societal concerns is crucial for the responsible development and deployment of multimodal LLMs:
-
Bias and Fairness: Ensuring fairness in multimodal models involves developing methods to detect and mitigate biases in training data and model outputs. Addressing issues of representation and equity is essential for creating models that serve diverse populations fairly.
-
Privacy Concerns: Managing privacy and security issues associated with multimodal data is vital for maintaining user trust. Implementing robust data protection measures and ensuring compliance with privacy regulations will be key to responsible AI development.
Conclusion
The development of multimodal LLMs represents a significant advancement in artificial intelligence, bringing us closer to systems that can communicate and understand information as richly and intuitively as humans do. Despite the challenges in data representation, alignment, and computational efficiency, progress in unified representation learning, cross-modal attention mechanisms, and generative pretraining is paving the way for sophisticated multimodal models.
The potential applications of multimodal LLMs are vast, spanning content creation, education, and accessibility. As research and technology continue to evolve, multimodal LLMs will play an increasingly pivotal role in our digital interactions, transforming the way we create, learn, and access information.
Free Custom ChatGPT Bot with BotGPT
To harness the full potential of LLMs for your specific needs, consider creating a custom chatbot tailored to your data and requirements. Explore BotGPT to discover how you can leverage advanced AI technology to build personalized solutions and enhance your business or personal projects. By embracing the capabilities of BotGPT, you can stay ahead in the evolving landscape of AI and unlock new opportunities for innovation and interaction.
Discover the power of our versatile virtual assistant powered by cutting-edge GPT technology, tailored to meet your specific needs.
Features
-
Enhance Your Productivity: Transform your workflow with BotGPT’s efficiency. Get Started
-
Seamless Integration: Effortlessly integrate BotGPT into your applications. Learn More
-
Optimize Content Creation: Boost your content creation and editing with BotGPT. Try It Now
-
24/7 Virtual Assistance: Access BotGPT anytime, anywhere for instant support. Explore Here
-
Customizable Solutions: Tailor BotGPT to fit your business requirements perfectly. Customize Now
-
AI-driven Insights: Uncover valuable insights with BotGPT’s advanced AI capabilities. Discover More
-
Unlock Premium Features: Upgrade to BotGPT for exclusive features. Upgrade Today
About BotGPT Bot
BotGPT is a powerful chatbot driven by advanced GPT technology, designed for seamless integration across platforms. Enhance your productivity and creativity with BotGPT’s intelligent virtual assistance.